Lo Esencial de Slackware Linux
![]()
Alan Hicks
Chris Lumens
David Cantrell
Logan Johnson
Traducción: Nestor Alonso
Copyright © 1998, 1999, 2000, 2001, 2002, 2003, 2004, 2005 Slackware Linux, Inc.
Slackware Linux es marca registrada de Patrick Volkerding y Slackware Linux, Inc.
Linux es marca registrada de Linus Torvalds.
Red Hat, RPM, son marcas o marcas registradas de Red Hat, Inc. en los Estados Unidos y otros países.
- Tabla de Contenidos
- Prefacio
- 1 Introducción a Slackware Linux
- 2 Ayuda
-
- 2.1 Ayuda del Sistema
-
- 2.1.1 man
- 2.1.2 El Directorio /usr/doc
- 2.1.3 HOWTOs y mini-HOWTOs
- 2.2 Ayuda en Línea
- 3 Instalación
-
- 3.1 Obteniendo Slackware
-
- 3.1.1 La Caja y Juego de Discos Oficiales
- 3.1.2 Via Internet
- 3.2 Requerimientos del Sistema
-
- 3.2.1 Las Series de Software
- 3.2.2 Métodos de Instalación
- 3.2.3 Disquetes de Inicio
- 3.2.4 Disquete Root
- 3.2.5 Disquete Suplementario
- 3.2.6 Haciendo los Discos
- 3.3 Particionando
- 3.4 El Programa setup
- 4 Configuración del Sistema
- 5 Configuracion de Red
-
- 5.1 Introducción: netconfig es su amigo
- 5.2 Configuración del Hardware de Red
-
- 5.2.1 Cargando los Módulos de Red
- 5.2.2 Tarjetas LAN (10/100/1000Base-T y Base-2)
- 5.2.3 Modems
- 5.2.4 PCMCIA
- 5.3 Configuración TCP/IP
-
- 5.3.1 DHCP
- 5.3.2 IP Estático
- 5.3.3 /etc/rc.d/rc.inet1.conf
- 5.3.4 /etc/resolv.conf
- 5.3.5 /etc/hosts
- 5.4 PPP
- 5.5 Wireless
-
- 5.5.1 Soporte de Hardware
- 5.5.2 Configurar las Opciones Wireless
- 5.5.3 Configurar la Red
- 5.6 Sistemas de Archivos en Red
-
- 5.6.1 SMB/Samba/CIFS
- 5.6.2 Network File System (NFS)
- 6 Configuración de X
-
- 6.1 xorgconfig
- 6.2 xorgsetup
- 6.3 xinitrc
- 6.4 xwmconfig
- 6.5 xdm
- 7 Iniciando
-
- 7.1 LILO
- 7.2 LOADLIN
- 7.3 Inicio Dual
- 8 La Consola
-
- 8.1 Usuarios
-
- 8.1.1 Iniciando Sesión
- 8.1.2 Root: El Superusuario
- 8.2 La línea de Comandos
- 8.3 El Bourne Again Shell (bash)
-
- 8.3.1 Variables de Entorno
- 8.3.2 Completamiento con Tab
- 8.4 Terminales Virtuales
-
- 8.4.1 Pantalla
- 9 Estructura del Sistema de Archivos
-
- 9.1 Propiedad
- 9.2 Permisos
- 9.3 Enlaces
- 9.4 Montando Dispositivos
-
- 9.4.1 fstab
- 9.4.2 mount y umount
- 9.5 Montando NFS
- 10 Gestionando Archivos y Directorios
- 11 Control de Procesos
-
- 11.1 Pasando a Segundo Plano
- 11.2 Pasando a Primer Plano
- 11.3 ps
- 11.4 kill
- 11.5 top
- 12 Administración Básica del Sistema
-
- 12.1 Usuarios y Grupos
-
- 12.1.1 Scripts Brindados
- 12.1.2 Cambiando Contraseñas
- 12.1.3 Cambiando Información de Usuario
- 12.2 Usuarios y Grupos, La Manera Difícil
- 12.3 Apagando Adecuadamente
- 13 Comandos Básicos de Red
-
- 13.1 ping
- 13.2 traceroute
- 13.3 Herramientas DNS
- 13.4 finger
- 13.5 telnet
-
- 13.5.1 El otro uso de telnet
- 13.6 La Consola Segura
- 13.7 Correo Electrónico
- 13.8 Navegadores
- 13.9 Clientes FTP
- 13.10 Hablando con otras Personas
- 14 Seguridad
-
- 14.1 Deshabilitando Servicios
- 14.2 Control de Acceso al Host
-
- 14.2.1 iptables
- 14.2.2 tcpwrappers
- 14.3 Manteniéndose Actualizado
-
- 14.3.1 La Lista de Correos slackware-security
- 14.3.2 El directorio /patches
- 15 Compactando Archivos
- 16 Vi
-
- 16.1 Iniciando vi
- 16.2 Modos
-
- 16.2.1 Modo Comando
- 16.2.2 Modo Insertar
- 16.3 Abriendo Archivos
- 16.4 Salvando Archivos
- 16.5 Saliendo de vi
- 16.6 Configuración de vi
- 16.7 Teclas en Vi
- 17 Emacs
-
- 17.1 Iniciando emacs
-
- 17.1.1 Teclas de Comando
- 17.2 Buffers
- 17.3 Modos
-
- 17.3.1 Abriendo Archivos
- 17.4 Edición Básica
- 17.5 Salvando Archivos
-
- 17.5.1 Saliendo de Emacs
- 18 Gestión de Paquetes en Slackware
-
- 18.1 Panorámica del Formato de Paquetes
- 18.2 Herramientas de Paquetes
-
- 18.2.1 pkgtool
- 18.2.2 installpkg
- 18.2.3 removepkg
- 18.2.4 upgradepkg
- 18.2.5 rpm2tgz/rpm2targz
- 18.3 Haciendo Paquetes
-
- 18.3.1 explodepkg
- 18.3.2 makepkg
- 18.3.3 Scripts SlackBuild
- 18.4 Haciendo Tags y Archivos de tags (para setup)
- 19 ZipSlack
-
- 19.1 ¿Qué es ZipSlack?
-
- 19.1.1 Ventajas
- 19.1.2 Desventajas
- 19.2 Obteniendo ZipSlack
-
- 19.2.1 Instalación
- 19.3 Iniciando ZipSlack
- Glosario
- A. La Licencia General Pública GNU
- Lista de Tablas
- 2-1. Secciones de las Páginas Man
- 3-1. Información de Contacto Slackware Linux, Inc.
- 3-2. Requerimientos del Sistema
- 3-3. Series de Software
- 9-1. Valores de Permisos Octales
- 13-1. Comandos ftp
- 16-1. Movimiento
- 16-2. Edición
- 16-3. Buscar
- 16-4. Salvar y Salir
- 17-1. Comandos Básicos de Edición en Emacs
- 18-1. Opciones de installpkg
- 18-2. Opciones de removepkg
- 18-3. Opciones de Estado en el Archivos de Tags
- Lista de Figuras
- 4-1. Menú de Configuración del Núcleo
- 6-1. xorgconfig Configuración del Ratón
- 6-2. xorgconfig Sincronismo Horizontal
- 6-3. xorgconfig Sincronismo Vertical
- 6-4. xorgconfig Adaptador de Vídeo
- 6-5. xorgconfig Configuración de Escritorio
- 7-1. liloconfig
- 7-2. liloconfig Menú Experto
- 11-1. Salida del comando ps
- 13-1. Haciendo Telnet a un servidor web
- 13-2. El menú principal de Pine
- 13-3. Pantalla principal de Elm
- 13-4. Pantalla principal de Mutt
- 13-5. Página de inicio por omisión de Lynx
- 13-6. Links, con el menú Archivo abierto
- 13-7. Dos usuarios en una sesión talk
- 13-8. Dos usuarios en una sesión ytalk
- 16-1. Una sesión vi.
- 18-1. Menú principal de Pkgtool.
- 18-2. Modo ver de Pkgtool
- Lista de Ejemplos
- 8-1. Mostrando las Variables de Entorno con set
Prefacio
Público Objetivo
Y ahora, que comience la función.
Cambios desde la Primera Edición
-
Capítulo 3, Instalación, ha sido modificado con nuevas capturas de pantalla del instalador, y refleja los cambios en los disquetes y en el CD de instalación.
-
Capítulo 4, Configuración del Sistema, ha sido actualizado con nueva información acerca de los núcleos Linux 2.6.x.
-
Capítulo 5, Configuración de Red, ha sido expandido con explicaciones de Samba, NFS y DHCP. Se ha adicionado una sección sobre redes inalámbricas. Este capítulo ahora refleja grandes cambios en la manera en que Slackware maneja la configuración de red.
-
Capítulo 6, El Sistema X Window, ha sido reescrito sustancialmente para los sistemas basados en Xorg. Este capítulo además cubre el gestor de inicio gráfico xdm.
-
Capítulo 13, Comandos Básicos de Red, han sido mejorados con información acerca de utilidades de red adicionales.
-
Capítulo 14, Seguridad, es un nuevo capítulo en esta edición. Explica como mantener un sistema Slackware Linux seguro.
-
Capítulo 17, Emacs, es un nuevo capítulo en esta edición. Describe como utilizar Emacs, un poderoso editor para Unix.
-
Capítulo 18, Gestión de Paquetes, ha sido actualizado con información acerca de los scripts SlackBuild.
-
Hay muchos otros cambios, tanto grandes como pequeños, para reflejar los cambios en Slackware en la medida en que ha madurado.
Organización de este Libro
- Capítulo 1, Introducción
-
Brinda material introductorio acerca de Linux, Slackware, los movimientos de Código Abierto y Software Libre.
- Capítulo 2, Ayuda
-
Describe los recursos de ayuda disponibles en el sistema Slackware Linux y en línea.
- Capítulo 3, Instalación
-
Describe el proceso de instalación paso a paso con capturas de pantalla para brindar un recorrido ilustrativo.
- Capítulo 4, Configuración del Sistema
-
Describe los importantes archivos de configuración y cubre la recompilación del núcleo.
- Capítulo 5, Configuración de Red
-
Describe como conectar una máquina Slackware Linux a una red. Cubre TCP/IP, PPP/marcado, redes inalámbricas, y más.
- Capítulo 6, El Sistema X Window
-
Describe como configurar y usar el Sistema Gráfico X Window en Slackware.
- Capítulo 7, Arranque
-
Describe el proceso mediante el cual una computadora arranca en Slackware Linux. También cubre el arranque dual con sistemas operativos Microsoft Windows.
- Capítulo 8, La Consola
-
Describe la poderosa interfaz de comandos de Linux.
- Capítulo 9, Estructura del Sistema de Archivos
-
Describe la estructura del sistema de archivos, incluyendo propiedad, permisos y enlaces.
- Capítulo 10, Gestionando Archivos y Directorios
-
Describe los comandos utilizados para manipular ficheros y directorios desde la interfaz de la línea de comandos.
- Capítulo 11, Control de Procesos
-
Describe los poderosos comandos para el manejo de procesos, utilizados para gestionar múltiples aplicaciones simultáneamente.
- Capítulo 12, Administración Básica del Sistema
-
Describe tareas básicas de administración del sistema, como adicionar y eliminar usuarios, apagar el sistema correctamente, y más.
- Capítulo 13, Comandos Básicos de Red
-
Describe la colección de clientes de red incluidos con Slackware.
- Capítulo 14, Seguridad
-
Describe muchas herramientas diferentes, disponibles para ayudar a mantener su sistema Slackware seguro, incluyendo iptables y tcpwrappers.
- Capítulo 15, Compactando Archivos
-
Describe las diferentes utilidades para compactar y agrupar, disponibles para Linux.
- Capítulo 16, vi
-
Describe el potente editor de texto vi.
- Capítulo 17, Emacs
-
Describe el potente editor de texto Emacs.
- Capítulo 18, Gestión de Paquetes Slackware
-
Describe las utilidades de paquetes y los procesos utilizados para crear paquetes personalizados y archivos de descripción.
- Capítulo 19, ZipSlack
-
Describe la versión de Linux ZipSlack que puede ser utilizada desde Windows sin necesidad de instalación.
- Apéndice A, La Licencia General Pública GNU.
-
Describe los términos de licencia bajo los cuales Slackware Linux y este libro pueden ser copiados y distribuidos.
Convenciones utilizadas en este libro
Convenciones Tipográficas
Entrada de Usuario
Significa que el usuario debe teclear Ctrl, Alt, y Del al mismo tiempo.
Las teclas que se supone que se tecleen en secuencia serán separadas con comas, por ejemplo:
Ejemplos
D:\> rawrite a: bare.i
|
# dd if=bare.i of=/dev/fd0
|
% top
|
Reconocimientos
Capítulo 1 Introducción a Slackware Linux
1.1 ¿Qué es Linux?
Linus Torvalds comenzó Linux, el núcleo de un sistema operativo, como un proyecto personal en 1991. Él comenzó el proyecto debido a que quería correr un sistema operativo basado en Unix sin pagar mucho dinero. Además, quería aprender los pormenores del procesador 386. Linux fue entregado libre de cargos al público de manera que cualquier persona podía estudiarlo y hacerle mejoras bajo la Licencia Pública General. (Ver la Sección 1.3 y Apéndice A para una explicación de la licencia.) Hoy, Linux ha crecido hasta convertirse en un gran jugador en el mercado de los sistemas operativos. Ha sido portado para correr en una variedad de arquitecturas de sistema, incluyendo HP/Alpha de Compaq, SPARC de Sun y UltraSPARC, y los chips PowerPC de Motorola (a través de Apple Macintosh y las computadoras IBM RS/6000.) Cientos, si no miles, de programadores alrededor del mundo ahora desarrollan Linux. Corre programas como Sendmail, Apache, y BIND, los cuales son programas muy populares acostumbrados a correr en servidores de Internet. Es importante recordar que el término “Linux” realmente se refiere al núcleo - el centro del sistema operativo. Este núcleo es el responsable de controlar el procesador de su computadora, así como la memoria, discos duros, y periféricos. Esto es todo lo que Linux realmente hace: Controla las operaciones de su computadora y se asegura de que todos sus programas se comporten correctamente. Varias compañías y personas empaquetan el núcleo y varios programas para hacer un sistema operativo. Llamaremos a cada paquete de este tipo una distribución de Linux.
1.1.1 Unas palabras sobre GNU
El proyecto del núcleo de Linux comenzó como un esfuerzo personal de Linus Torvalds en 1991, pero tal como dijo Isaac Newton, “Si he visto más allá, es porque he estado parado en hombros de gigantes.” Cuando Linus Torvalds comenzó el núcleo, la Fundación de Software Libre había establecido ya la idea del software colaborativo. Ellos llamaron a su esfuerzo GNU, un acrónimo recursivo que simplemente significa “GNU's Not Unix”. El software GNU corrió sobre el núcleo de Linux desde su primer día. Su compilador gcc fue utilizado para compilar el núcleo. Hoy muchas herramientas GNU desde gcc hasta gnutar son todavía las bases de la mayoría de las distribuciones de Linux. Por esta razón muchos de los autores de la Fundación de Software Libre mantienen fervientemente que su trabajo merece el mismo crédito que el núcleo de Linux. Ellos sugieren que todas las distribuciones de Linux deben referirse a sí mismas como distribuciones GNU/Linux.
Este es el asunto de muchas discusiones, sobrepasadas solamente por la antigua guerra santa vi versus emacs. El propósito de este libro no es atizar el fuego sobre esta discusión de por sí caliente, sino aclarar la terminología a los neófitos. Cuando uno ve GNU/Linux esto significa una distribución de Linux. Cuando uno ve solamente Linux, puede ser bien el núcleo, o la distribución. Esto puede ser algo confuso. Típicamente el término GNU/Linux no se utiliza porque es no es fácil de pronunciar.
1.2 ¿Qué es Slackware?
Slackware, comenzado por Patrick Volkerding a finales de 1992, e inicialmente liberado al mundo el 17 de Julio de 1993, fue la primera distribución de Linux en alcanzar un uso masivo. Volkerding comenzó a aprender Linux cuando necesitó un intérprete de LISP barato para un proyecto. Una de las pocas distribuciones disponibles en ese entonces era SLS Linux de Soft Landing Systems. Volkerding usó SLS Linux, reparando errores en la medida en que los encontraba. Eventualmente, decidió unir todos esos arreglos en su propia distribución privada, que él y sus amigos pudieran usar. Esta distribución privada rápidamente ganó popularidad, de manera que Volkerding decidió llamarla Slackware y hacerla disponible públicamente. Por el camino, Patrick adicionó nuevas cosas a Slackware; un programa de instalación amigable al usuario basado en menúes, así como el concepto de gestión de paquetes, el cual le permite al usuario fácilmente adicionar, eliminar, o actualizar paquetes de software en su sistema.
Existen varias razones por las cuales Slackware es la distribución de Linux más antigua que aún existe. No intenta emular a Windows; trata de ser un sistema tan parecido a Unix como sea posible. No trata de cubrir los procesos con interfaces gráficas bonitas que permitan apuntar-y-presionar. En cambio, pone al usuario en los controles, dejándole ver exactamente que está sucediendo. Su desarrollo no está apurado para cumplir metas-cada versión sale cuando está lista.
Slackware es para la gente que disfruta aprendiendo y ajustando su sistema para que haga exactamente los que ellos quieren que haga. La estabilidad y simplicidad de Slackware son las razones por las cuales la gente lo seguirá usando en los años venideros. Slackware actualmente disfruta una buena reputación como servidor sólido y como estación coherente. Es posible encontrar escritorios Slackware corriendo casi cualquier gestor de ventanas o entorno de escritorio, o ninguno en absoluto. Los servidores Slackware dan potencia a negocios, actuando en cada lugar donde un servidor pueda ser utilizado. Los usuarios de Slackware están entre los más satisfechos usuarios de Linux. Por supuesto, debemos decir eso. :^)
1.3 Código Abierto y Software Libre
En la comunidad Linux, existen dos movimientos ideológicos principales influyendo. El movimiento de Software Libre (el cual veremos en un momento) está trabajando hacia el objetivo de hacer todo el software libre de restricciones de propiedad intelectual. Los seguidores de este movimiento creen que estas restricciones frenan las mejoras técnicas y se oponen al bien de la comunidad. El movimiento de Código Abierto trabaja sobre las mismas metas, pero toma un comportamiento más pragmático. Los seguidores de este movimiento prefieren basar sus argumentos en los méritos técnicos y económicos de hacer disponible públicamente el código fuente, en vez de basarlos en los principios morales y éticos que manejan el Movimiento del Software Libre.
En el otro extremo del espectro están los grupos que desean mantener un férreo control sobre su software.
El movimiento de Software Libre está encabezado por la Fundación por el Software Libre (Free Software Foundation), organización que recoge fondos para el proyecto GNU. El software libre es más que una ideología. La expresión utilizada para aclarar este concepto es “free as in speech, not free as in beer” (Libre como la expresión, no gratis como la cerveza). En esencia, el software libre es un intento de garantizar ciertos derechos, tanto para los clientes como para los desarrolladores. Estas libertades incluyen la libertad de correr el programa para cualquier fin, para estudiar y modificar el código fuente, para redistribuir las fuentes, y para compartir las modificaciones que se realicen. Para garantizar estas libertades fue creada la Licencia Pública General GNU (GPL). La GPL, en resumen, dice que cualquiera que distribuya un programa compilado que se encuentre bajo la GPL debe brindar el código fuente, y es libre de hacer modificaciones al programa siempre que estas modificaciones se hagan también disponibles en forma de código fuente. Esto garantiza que una vez que un programa se "abra" a la comunidad, no pueda ser cerrado de nuevo, excepto bajo el consentimiento del autor de cada línea de código que se encuentre en el programa (incluso de las modificaciones). La mayor parte de los programas para Linux están licenciados bajo la GPL.
Es importante notar que la GPL no dice nada acerca de precio. Tan extraño como parezca, es posible cobrar por el software libre. La parte "libre" está en las libertades que existen con las fuentes, no en el precio que puede pagarse por el software. (De todas formas, una vez que alguien le haya vendido, o incluso regalado, un programa compilado bajo la GPL, esa persona contrae la obligación de darle también el código fuente).
Otra licencia popular es la licencia BSD. En contraste con la GPL, la licencia BSD no obliga a que se libere el código fuente del programa. El software bajo la licencia BSD permite redistribuciones en fuentes o en binarios, solamente cumpliendo unas pocas condiciones. Las credenciales del autor no pueden ser utilizadas como publicidad para el programa. También indemniza al autor de las responsabilidades por daños que puedan derivarse del uso del software. Gran parte del software incluido en Slackware Linux posee licencia BSD.
A la vanguardia del movimiento de Código Abierto -más joven-, la Iniciativa por el Código Abierto (Open Source Initiative, OSI) es una organización que existe con el fin de obtener soporte para el software de código abierto, o sea, el software que tenga el código fuente disponible, así como el programa listo-para-correr. Ellos no ofrecen una licencia específica, sino que dan soporte a las diferentes licencias de código abierto existentes.
La idea detrás de OSI es lograr que más compañías respalden el código abierto, permitiéndoles escribir sus propias licencias de código abierto y certificarlas bajo las normas de la OSI. Muchas compañías desean liberar su código fuente, pero no desean utilizar la GPL. Teniendo en cuenta que no pueden modificar radicalmente la GPL, se les ofrece la oportunidad de que brinden sus propias licencias y que las tengan certificadas por esta organización.
A pesar de que la Fundación por el Software Libre y la Iniciativa por el Código Abierto trabajan para ayudarse, no son la misma cosa. La Fundación por el Software Libre usa una licencia específica y brinda software bajo esta licencia. La Iniciativa por el Código Abierto busca soporte para todas las licencias de código abierto, incluyendo la de la Fundación por el Software Libre. Las bases sobre las cuales cada una discute para hacer que el código fuente esté disponible libremente a veces divide a ambos movimientos, pero el hecho de que dos grupos ideológicamente diversos estén trabajando en pos de la misma meta le da credibilidad a los esfuerzos de cada uno.
Capítulo 2 Ayuda
2.1 Ayuda del Sistema
2.1.1 man
El comando man (abreviatura de “manual”) es la forma tradicional de documentación en línea en los sistemas operativos Unix y Linux. Compuesto por archivos con un formato especial, las “páginas man”, están escritas para la amplia mayoría de los comandos y se distribuyen con el software en sí. Si se ejecuta man algúncomando, se mostrará la página man para (naturalmente) el comando especificado, en nuestro ejemplo sería el programa imaginario algúncomando
Como usted puede imaginar, la cantidad de páginas man puede fácilmente crecer, haciéndose sobre todo confusas y seriamente complicadas, incluso para un usuario avanzado. Entonces, por esta razón, las páginas man están agrupadas en secciones enumeradas. Este sistema ya lleva funcionando bastante tiempo; el suficiente como para que a veces comandos, programas, e incluso funciones de bibliotecas de programación, sean referidas con su número de sección man.
Por ejemplo:
Usted puede ver una referencia a man(1). La numeración le dice que este “man” está documentado en la sección 1 (comandos de usuario); usted puede especificar que desea la sección 1 de las páginas man para “man” con el comando man 1 man. Especificando la sección en la que man debe buscar es útil en el caso de que haya múltiples artículos con el mismo nombre.
Tabla 2-1. Secciones de las Páginas Man
| Sección | Contenido |
|---|---|
| Sección 1 | comandos de usuario (solo introducción) |
| Sección 2 | llamadas de sistema |
| Sección 3 | llamadas de bibliotecas C |
| Sección 4 | dispositivos (p.e. hd, sd) |
| Sección 5 | formatos de archivo y protocolos (p.e. wtmp, /etc/passwd, nfs) |
| Sección 6 | juegos (solo introducción) |
| Sección 7 | convenciones, paquetes macro, etc. (p.e. nroff, ascii) |
| Sección 8 | administración del sistema (solo introducción) |
% whatis whatis |
El comando apropos se utiliza para buscar una página man que contenga una palabra clave dada.
% apropos wav |
2.1.2 El Directorio /usr/doc
La fuente de la mayoría de los paquetes que construimos viene con alguna clase de documentación: archivos README, instrucciones de uso, archivos de licencia, etc. Cualquier clase de documentación que venga con la fuente se incluye e instala en su sistema en el directorio /usr/doc. Cada programa va (usualmente) a instalar su propia documentación siguiendo el orden:
/usr/doc/$programa-$versión
Donde $programa es el nombre del programa sobre el cual usted desea leer, y $versión es (obviamente) la versión apropiada del paquete de software instalado en su sistema.
Por ejemplo, para leer la documentación para el comando man(1) usted debe hacer cd a:
% cd /usr/doc/man-$versión
|
Si leyendo la(s) página(s) man apropiada(s) no obtiene la suficiente información, o dirección que usted está buscando en particular, el directorio /usr/doc debe ser su próxima parada.
2.1.3 HOWTOs y mini-HOWTOs
Está en el más verdadero espíritu de la comunidad de Código Abierto el hecho de brindarnos la colección de HOWTO/mini-HOWTO (CÓMOs/mini-CÓMOs). Estos archivos son exactamente eso - documentos y guías que describen como hacer algo. Si usted instaló la colección de HOWTO, los HOWTOs estarán instalados en /usr/doc/Linux-HOWTOs y los mini-HOWTOs en /usr/doc/Linux-mini-HOWTOs.
También se incluyen en la misma serie de paquetes una colección de FAQs, cuyo acrónimo significa:
2.2 Ayuda en Línea
Además de la documentación brindada e instalable con el Sistema Operativo Slackware Linux , existe una vasta multitud de recursos en línea disponibles para que usted aprenda de ellos también.
2.2.1 El Sitio Web Oficial y los Foros de Ayuda
El Sitio Web Oficial de Slackware
El Sitio Web Oficial de Slackware Linux está a veces desactualizado, pero aún así contiene información relevante para las últimas versiones de Slackware. Una vez existió un foro activo de ayuda, antes que hordas de trolls, buscaproblemas, y llorones descendieran a él. Mantener el foro se estaba haciendo demasiado trabajo, así que Pat lo cerró. Uno puede hallar el viejo foro respaldado y corriendo completo con archivos donde es posible buscar la información vieja en http://www.userlocal.com/phorum/.
Después de que los foros se bajaran de http://slackware.com, otros sitios ofrecieron soporte para Slackware. Después de mucho pensar, Pat decidió nombrar a www.linuxquestions.org como el foro oficial para Slackware Linux.
2.2.2 Soporte por Correo Electrónico
Todo aquel que compre un grupo de CDs Oficiales tiene derecho a soporte gratis de instalación por correo electrónico. Habiendo dicho esto, por favor, tenga en mente que nosotros, los desarrolladores, (y la gran mayoría de usuarios) de Slackware somos de “La Vieja Escuela”. Esto significa que preferimos ayudar a aquellos que tienen un sincero interés y tratan de ayudarse a sí mismos en el proceso. Nosotros siempre haremos nuestro mayor esfuerzo para ayudar a todos aquellos que nos envíe un correo con preguntas de soporte. De todas formas, Por Favor, revise su documentación y el sitio web (especialmente las FAQs y tal vez alguno de los foros que listamos más abajo) antes de enviar un correo. Así, usted puede obtener una respuesta más rápida, y nosotros tendremos que responder menos correos, obviamente, brindando más rápido nuestra ayuda a aquellos que la necesiten.
La dirección de correo electrónico para soporte técnico es support@slackware.com. Otras direcciones de correo e información de contacto se listan en el sitio web.
2.2.2.1 Las Listas de Correo del Proyecto Slackware Linux
Nosotros tenemos muchas listas de correo, disponibles en forma normal y digest. Revise las instrucciones para suscribirse.
Para suscribirse a una lista de correos, escriba a:
majordomo@slackware.com
con la frase “subscribe [nombre de lista]” en el cuerpo del mensaje. Las opciones de la lista se describen debajo (use uno de los nombres de abajo para el nombre de la lista).
Los archivos de la lista de correos pueden encontrarse en el sitio web de Slackware en:
http://slackware.com/lists/archive/
- slackware-announce
-
La lista de correo slackware-announce es para los anuncios de nuevas versiones, actualizaciones mayores y otra información general.
- slackware-security
-
La lista de correo slackware-security es para anuncios relativos a asuntos de seguridad. Cualquier exploit o vulnerabilidad que afecten directamente a Slackware va a ser enviado a esta lista inmediatamente.
Estas listas también están disponibles en modo digest. Esto significa que usted recibe solo un mensaje largo al día, en vez de varios mensajes durante día. Teniendo en cuenta de las listas de correo de Slackware no le permiten a los usuarios enviar correos, y las listas tienen poco tráfico, la mayoría de los usuarios obtienen pocas ventajas del modo digest. De todas maneras, están disponibles suscribiéndose a slackware-announce-digest o slackware-security-digest.
2.2.3 Sitios Web No Oficiales y Foros de Ayuda
2.2.3.1 Sitios Web
-
El Maestro de Kung-Fu de los Buscadores. Donde usted va a encontrar absoluta y positivamente hasta el último reducto de información sobre cualquier asunto. No acepta sustitutos.
- Google:Linux
-
Búsquedas específicas sobre Linux
- Google:BSD
-
Búsquedas específicas sobre BSD. Slackware es tan genérico como sistema operativo al estilo Unix que uno puede encontrar información casi 100% relevante aquí. Muchas veces una búsqueda BSD revela mucha más información técnica que una relacionada con Linux.
- Google:Groups
-
Busca a través de décadas de envíos a Usenet.
- http://userlocal.com
-
Un tesoro virtual de conocimiento, buenos avisos, experiencia de primera mano y artículos interesantes. Frecuentemente el primer lugar donde se escucha sobre los nuevos desarrollos en el mundo de Slackware.
2.2.3.2 Recursos Basados en la Web
- linuxquestions.org
-
El foro web oficialmente seleccionado para los usuarios de Slackware.
- LinuxISO.org Slackware Forum
-
“Un lugar para descargar y obtener ayuda con Linux.”
- alt.os.linux.slackware FAQ
-
Otras FAQ
2.2.3.3 Grupos Usenet (NNTP)
Usenet hace mucho que es el lugar donde los geeks se reúnen y se ayudan unos a otros. Existen pocos grupos de noticias dedicados a Slackware Linux, pero tienden a estar llenos con personas de mucho conocimiento.
alt.os.linux.slackware
alt.os.linux.slackware, más conocido como aols (¡no confundirse con AOL®!) es uno de los lugares más activos para encontrar ayuda con los problemas de Slackware. Como todo grupo de noticias, unos pocos participantes que no ayudan (“trolls”) pueden estropear la experiencia . Aprender a ignorar los trolls e identificar a las personas que realmente ayudan es la clave para sacar lo máximo de este recurso.
Capítulo 3 Instalación
3.1 Obteniendo Slackware
3.1.1 La Caja y Juego de Discos Oficiales
El juego de CDs oficiales de Slackware Linux CD está disponible desde Slackware Linux, Inc. El juego consta de 4 discos. El primer disco contiene todo el software necesario para una instalación básica de servidor, y el sistema X window. El segundo cd es un “live” cd; esto es, un cd de inicio capaz de instalarse en la RAM y le brinda una instalación temporal para jugar con ella o para hacer un rescate de datos o de máquina. Este CD también contiene unos pocos paquetes como los entornos de escritorio KDE y GNOME. Unas cuantas mejoras se incluyen en el segundo cd, como paquetes no vitales en la carpeta “extra”. El tercero y cuarto CDs contienen el código fuente de todo Slackware, así como la edición original de este libro.
Uno puede también comprar una Caja que incluye los 4 discos y una copia de este libro (la edición en inglés), así como muchos pertrechos Slackware puros para mostrarlos como orgullo geek. Las suscripciones al CD están disponibles a un precio reducido, también.
El método preferido para comprar Slackware es en línea en la tienda Slackware.
Usted puede también llamar o mandar su orden por correo.
Tabla 3-1. Información de Contacto Slackware Linux, Inc.
| Método | Detalles de Contacto |
|---|---|
| Teléfono | 1-(925) 674-0783 |
| Sitio Web | http://store.slackware.com |
| Correo Electrónico | orders@slackware.com |
| Postal | 1164 Claremont Drive, Brentwood, CA 94513 |
3.1.2 Via Internet
Slackware Linux también está disponible libremente en Internet. Usted puede enviarnos un mensaje con sus preguntas de soporte, pero la prioridad más alta será dada a aquellos que compren el juego de CDs oficiales. Dicho esto, nosotros recibimos muchos mensajes y nuestro tiempo es bastante limitado. Antes de enviar un mensaje para soporte considere leer el Capítulo 2.
El sitio web del Proyecto oficial Slackware Linux se encuentra en:
La localización FTP primaria para Slackware Linux es:
ftp://ftp.slackware.com/pub/slackware/
Tenga en mente que nuestro sitio ftp, aunque está abierto para uso general, no tiene ancho de banda ilimitado. Por favor considere usar un servidor espejo cercano a usted para descargar Slackware. Una lista incompleta de los espejos puede encontrarse en nuestro sitio, en:
3.2 Requerimientos del Sistema
Una instalación sencilla de Slackware requiere, como mínimo, lo siguiente:
Tabla 3-2. Requerimientos del Sistema
| Hardware | Requerimiento |
|---|---|
| Procesador | 586 |
| RAM | 32 MB |
| Espacio en Disco | 1GB |
| Unidad | 4x CD-ROM |
3.2.1 Las Series de Software
Por razones de simplicidad, Slackware ha sido dividido históricamente en series de software. Incluso se llamaron “grupo de discos” debido a que fueron diseñados para la instalación basada en disquetes. Actualmente, las series de software se utilizan básicamente para categorizar los paquetes incluidos en Slackware, pues la instalación desde disquetes ya no es posible.
A continuación se describen brevemente las series de software:
| Series | Contenido |
|---|---|
| A | El sistema base. Contiene suficiente software para levantar y correr una máquina, tener un editor de texto y programas básicos de comunicaciones. |
| AP | Aplicaciones Varias que no requieren el sistema X Window. |
| D | Herramientas de Desarrollo de Programas. Compiladores, Debugueadores, intérpretes, y las páginas man están aquí. |
| E | GNU Emacs. |
| F | FAQs, HOWTOs, y otras documentaciones sobre misceláneas. |
| GNOME | El entorno de escritorio GNOME. |
| K | El código fuente del núcleo de Linux. |
| KDE | El Entorno de Escritorio K. Un entorno X que comparte parecido y características con MacOS y Windows. La biblioteca Qt, que necesita KDE, está también en esta serie. |
| KDEI | Paquetes de internacionalización para el escritorio KDE. |
| L | Bibliotecas. Bibliotecas enlazadas dinámicamente requeridas por muchos otros programas. |
| N | Programas para Redes. Demonios, programas de correo, telnet, lectores de noticias, y cosas por el estilo. |
| T | Sistema de formateo de documentos teTeX |
| TCL | El "Tool Command Language". Tk, TclX, y TkDesk. |
| X | El Sistema base X Windows. |
| XAP | Aplicaciones X que no son parte de los grandes entornos de escritorios (por ejemplo, Ghostscript y Netscape). |
| Y | Juegos de Consola BSD |
3.2.2 Métodos de Instalación
3.2.2.1 Disquetes
Aunque hace tiempo fue posible instalar todo Slackware Linux desde disquetes, el tamaño en aumento de los paquetes de software (incluso, de algunos programas individualmente) ha forzado el abandono de la instalación desde disquetes. Hasta la versión 7.1 de Slackware una instalación parcial era posible, utilizando disquetes. Las series A y N podían ser instaladas casi en su totalidad, brindando un sistema básico desde el cual era posible instalar el resto de la distribución. Si usted está considerando una instalación desde disquetes (típica de hardware antiguo) es típico recomendar que busque otra manera, o que utilice una versión más vieja de Slackware. Slackware 4.0 es aun muy popular por esta razón, así como 7.0.
Por favor, note que los disquetes aún son necesarios para una instalación desde CD-ROM si usted no posee un CD autoarrancable, así como para una instalación NFS.
3.2.2.2 CD-ROM
Si usted posee el CD autoarrancable, disponible en el juego de discos oficiales publicado por Slackware Linux Inc. (ver la sección llamada Obteniendo Slackware), la instalación basada en CD va a ser un poco más simple para usted. Si no, usted necesitará arrancar desde disquetes. También, si usted posee hardware especial que hace problemático el uso del núcleo que viene en el CD autoarrancable, necesitará utilizar disquetes especializados.
Desde Slackware versión 8.1, es utilizado un nuevo método para crear los CDs autoarrancables, el cual no funciona bien con ciertos BIOS (debe notarse que la mayoría de los CDs arrancables de Linux sufren esta dolencia). Si este es el caso, le recomendamos arrancar desde un disquete.
La Sección 3.2.3 y Sección 3.2.5 brinda información a la hora de escoger y crear disquetes para decidir desde cual arrancar, en caso de que fuera necesario.
3.2.2.3 NFS
NFS (el Sistema de Archivos en Red (Network File System)) es una manera de hacer los sistemas de archivos disponibles para máquinas remotas. Una instalación desde NFS permite instalar Slackware desde otra computadora en la red. La máquina desde la cual usted está instalando necesita configurarse para exportar el árbol de la distribución de Slackware a la máquina en la cual usted está instalando. Esto, por supuesto, incluye algunos conocimientos de NFS, el cual se explica en la Sección 5.6.
Es posible realizar una instalación NFS mediante métodos como PLIP (sobre puerto paralelo), SLIP, y PPP (aunque no sobre una conexión de modem). De todas formas, recomendamos utilizar una tarjeta de red, si estuviera disponible. Después de todo, instalar un sistema operativo mediante el puerto de impresoras es un proceso muy, muy lento.
3.2.3 Disquetes de Inicio
El disquete de inicio es el disquete desde el cual usted arranca para comenzar la instalación. Este contiene una imagen comprimida del núcleo la cual se utiliza para controlar el hardware durante la instalación. Por ende es algo muy necesario (a menos que esté iniciando desde CD, como se explica en la sección llamada CD-ROM). Los disquetes de inicio se encuentran en el directorio bootdisks/ en el árbol de la distribución.
Existen más disquetes de inicio de Slackware, como podrá observar (digamos, alrededor de 16). Una lista completa, con una descripción de cada uno, es posible encontrarla en el árbol de la distribución de Slackware en bootdisks/README.TXT. De todas maneras, la mayoría de las personas pueden utilizar la imagen de disquete de inicio bare.i (para dispositivos IDE) o scsi.s (para dispositivos SCSI).
Vea la Sección 3.2.6 para obtener las instrucciones de cómo hacer un disquete desde una imagen.
Después de iniciar, se le va a solicitar que inserte el disco "root". Nosotros recomendamos que en este punto sencillamente juegue con el disco y continúe.
3.2.4 Disquete Root
El disquete root contiene el programa de instalación y el sistema de archivos que será utilizado durante la instalación. Estos también son necesarios. La imagen del disquete root se encuentra en el directorio rootdisks en el árbol de la distribución. Usted tendrá que hacer dos disquetes root desde las imágenes install.1 e install.2. Aquí puede también encontrar los discos network.dsk, pcmcia.dsk, rescue.dsk, y sbootmgr.dsk.
3.2.5 Disquete Suplementario
El disco suplementario es necesario en caso de que usted esté realizando una instalación desde NFS o al instalar en un sistema con dispositivos PCMCIA. Los discos suplementarios están en el directorio de los discos root, con los nombres de archivo network.dsk y pcmcia.dsk. Recientemente, otros discos suplementarios han sido añadidos, como por ejemplo rescue.dsk y sbootmgr.dsk. El disco de rescate (rescue) es una pequeña imagen del disco root que corre en unidades con 4 MB de RAM. Incluye algunas utilidades básicas de redes, como el editor vi, para hacer reparaciones rápidas en máquinas con problemas. El disco sbootmgr.dsk se utiliza para levantar otros dispositivos. Levante desde este disco si su CD-ROM autoarrancable no quiere iniciar los CDs de Slackware. Este disco le debe preguntar por diferentes cosas para levantar, y puede ser una manera conveniente de escaparse de un BIOS defectuoso.
El disco root va a darle las instrucciones en el uso de los discos suplementarios cuando este cargue.
3.2.6 Haciendo los Discos
Una vez que usted ha seleccionado una imagen de un disco de arranque, necesita ponerla en un disquete. EL proceso es ligeramente diferente en dependencia de que sistema operativo esté usando para hacer los discos. Si usted está corriendo Linux (o casi cualquier sistema al estilo Unix) usted va a necesitar utilizar el comando dd(1). Asumiendo que bare.i es el archivo imagen de su disco y que su unidad de disquetes es /dev/fd0, el comando para hacer un disquete bare.i es:
% dd if=bare.i of=/dev/fd0
|
Si está corriendo un Sistema Operativo Microsoft, usted necesitará utilizar el programa RAWRITE.EXE, el cual está incluido en el árbol de la distribución en el mismo directorio que las imágenes de los disquetes. Una vez más, asumiendo que bare.i es su imagen de disco y que su unidad de disquete es A:, abra una consola de DOS y teclee lo siguiente:
C:\ rawrite a: bare.i
|
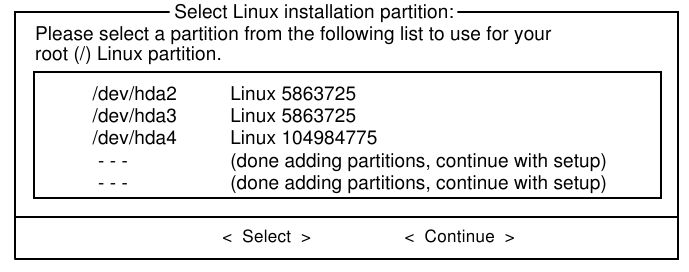
3.3 Particionando
Después de arrancar desde su medio preferido, usted necesitará particionar su disco duro. La partición de disco es donde el sistema de archivos de Linux será creado, y donde Slackware será instalado. Como mínimo recomendamos dos particiones; una para la raiz del sistema de archivos (/) y uno para el espacio de intercambio (swap).
Después que el disco root termine de cargar, le va a presentar a usted un prompt para iniciar sesión. Inicie sesión como root (no tiene contraseña). En la consola, corra o bien cfdisk(8) o fdisk(8). El programa cfdisk brinda una interfaz más amigable al usuario que el programa fdisk, pero carece de ciertas características. Explicaremos brevemente el programa fdisk a continuación.
Comience corriendo fdisk para su disco duro. En Linux, los discos duros no tienen como identificador las letras de las unidades, sino que se representan por un archivo. El primer disco duro IDE (master primario) es /dev/hda, el esclavo primario es /dev/hdb, y así. Los discos SCSI siguen la misma convención, solo que en forma de /dev/sdX. Usted necesitará para arrancar fdisk pasarle como parámetro su disco duro:
# fdisk /dev/hda
|
Como todo buen programa en Unix, fdisk te brinda un cursor (¿creías que te iba a dar un menú, no es verdad?). La primera cosa que usted debe hacer es examinar sus particiones actuales: Esto lo hacemos tecleando p en el cursor de fdisk:
Command (m for help): p
|
Esto mostrará toda clase de informaciones sobre sus particiones actuales. La mayoría de las personas seleccionan una torre libre para instalar en ella y eliminan todas las particiones existentes en ella para hacer espacio para las particiones de Linux.
 |
ES MUY IMPORTANTE QUE USTED RESPALDE CUALQUIER INFORMACIÓN QUE DESEE SALVAR ANTES DE DESTRUIR LA PARTICIÓN EN LA CUAL SE ENCUENTRA ESTA. |
No hay ninguna manera sencilla de recuperarse de la eliminación de una partición, así que siempre respalde antes de jugar con ellas.
Mirando la información de la tabla de particiones usted debe ver el número de la partición, el tamaño y el tipo. Hay más información, pero no se preocupe por ella a hora. Vamos a eliminar todas las particiones de la torre para crear las de Linux. Corremos el comando d para eliminarlas:
Command (m for help): d |
Este proceso debe continuarse para cada una de las particiones. Después de eliminar las particiones estamos listos para crear las de Linux. Tenemos una partición para la raíz del sistema de archivos y otra para el intercambio (swap). Nótese que los esquemas de particionamiento en Unix son motivo de muchas guerras, y la mayoría de los usuarios van a decirle la mejor manera de hacerlo. Como mínimo, usted debe crear una partición para / y otra para intercambio. Al pasar el tiempo, usted desarrollará un método que funcione bien para su caso.
Yo uso dos esquemas de particionamiento básico. El primero es para escritorio. Yo hago 4 particiones, /, /home, /usr/local, y swap. Esto me permite reinstalar o actualizar toda la instalación bajo / sin barrer mis archivos de datos que se encuentran bajo /home o mis programas compilados que se hallan bajo /usr/local. Para los servidores, yo frecuentemente reemplazo la partición /usr/local por la partición /var. Muchos servicios diferentes almacenan información en esta partición, y mantenerla separada de / tiene ciertos beneficios en el desempeño. Por ahora nos quedaremos con solo dos particiones: / y swap.
Ahora crearemos las particiones con el comando n:
Command (m for help): n |
Necesitará asegurarse de crear particiones primarias. La primera partición va a ser nuestra partición de intercambio. Le diremos a fdisk que cree la partición número 1 como partición primaria. Comenzaremos en el cilindro 0 y para el cilindro final teclearemos +64M. Esto nos dará una partición de 64 megabytes para intercambio. (El tamaño de la partición de intercambio que usted necesita depende de la cantidad de RAM que usted tenga. Es sabiduría convencional que un espacio de intercambio que sea el doble de la RAM debe ser creado.) Entonces definiremos que la partición número 2 comienza en el primer cilindro disponible y va a llegar hasta el final de la unidad.
Command (m for help):n |
Ya casi terminamos. Necesitamos cambiar el tipo de la primera partición a tipo 82 (Linux swap). Teclee t para cambiar el tipo, seleccione la primera partición, y teclee 82. Antes de escribir los cambios en el disco, usted debe mirar la nueva tabla de particiones una última vez. Utilice p en fdisk para mostrar la tabla de particiones. Si todo parece bien, teclee w para escribir sus cambios al disco y salir de fdisk.
3.4 El Programa setup
Una vez que usted haya creado sus particiones, usted está listo para instalar Slackware. El próximo paso en el proceso de instalación es correr el programa setup(8). Para hacer esto, simplemente teclee setup la consola. setup es un sistema basado en menúes para instalar los paquetes de Slackware y configurar su sistema.

3.4.1 HELP
Si esta es su primera vez que instala Slackware, usted quizás desee dar una vuelta por la pantalla de ayuda. Esta le dará una descripción de cada parte de setup (muy parecido a lo que estamos escribiendo ahora, pero con menos compromiso) y las instrucciones para navegar por el resto de la instalación.

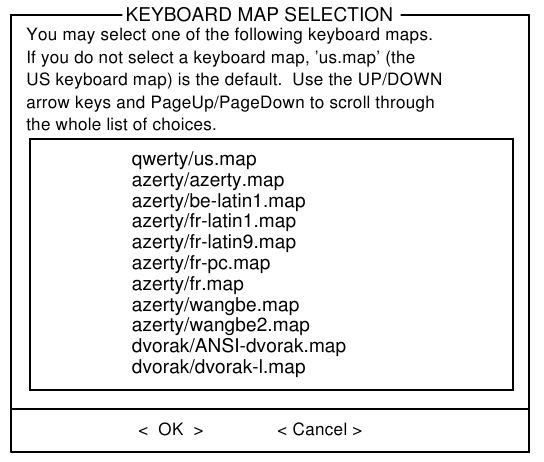
3.4.2 KEYMAP
Si usted requiere de otro mapa de teclado, distinto de la organización Estados Unidos “qwerty”, usted querrá mirar esta sección. Esta ofrece un número de organizaciones alternativas para su teclado.
3.4.3 ADDSWAP

Si usted creó una partición swap (regrese a la Sección 3.3), esta sección va a permitirle habilitarla. Esta va a autodetectar y mostrar las particiones de intercambio de su disco duro, permitiéndole seleccionar una para formatearla y habilitarla.
3.4.5 SOURCE
La sección "source" es donde usted selecciona el medio fuente desde donde instalar Slackware. Actualmente hay cuatro fuentes de donde seleccionar. Estas son CD-ROM, NFS, o un directorio premontado.

3.4.6 SELECT
La opción "select" le permite seleccionar las series de software que usted desea instalar. Estas series se describen en la Sección 3.2.1. Por favor note que usted debe instalar la serie A para obtener un sistema básico funcional. Todas las demás series son opcionales.

3.4.7 INSTALL
Asumiendo que usted haya ido a través de las opciones “target”, “source” y “select”, la opción install le permitirá seleccionar los paquetes de las series de software que usted escogió. Si no, le indicará que regrese y complete las otras opciones del menú de setup. Esta opción le permitirá escoger entre seis métodos de instalación diferentes: full, newbie, menu, expert, custom, y tag path.

Menu es una versión más rápida y avanzada que la opción newbie. Para cada serie, se muestra un menú, desde el cual usted puede seleccionar todos los paquetes no requeridos que desee instalar. Los paquetes requeridos no se muestran en este menú.
Las opciones custom y tag path son también para usuarios avanzados. Estas opciones le permiten instalar basado en los archivos de tags que usted haya creado en el árbol de la distribución. Esto es útil para instalar en un gran número de máquinas muy rápidamente. Para más información utilizando los archivos de tags, ver la Sección 18.4.
Después de seleccionar el método de instalación, una de pocas cosas sucederá. Si usted selecciona "full" o "menu", una pantalla de menú aparecerá, permitiendo seleccionar los paquetes que serán instalados. Si usted selecciona "full", los paquetes inmediatamente comenzarán a ser instalados donde se haya especificado. Si usted selecciona "newbie", los paquetes serán instalados hasta que llegue alguno opcional.
Note que es posible quedarse sin espacio mientras está instalando. Si usted selecciona demasiados paquetes para la cantidad de espacio libre en el dispositivo, tendrá problemas. La opción más segura es seleccionar pocos paquetes, y adicionar más posteriormente, en la medida en que los necesite. Esto puede ser hecho fácilmente utilizando las herramientas de gestión de paquetes de Slackware. Para obtener esta información, vea el Capítulo 18.
3.4.8 CONFIGURE
La sección "configure" le permite hacer algunas configuraciones básicas del sistema, una vez que los paquetes han sido instalados. Lo que verá en esta sección depende en gran parte de los paquetes de software que hayan sido instalados. De cualquier manera, usted siempre verá lo siguiente:
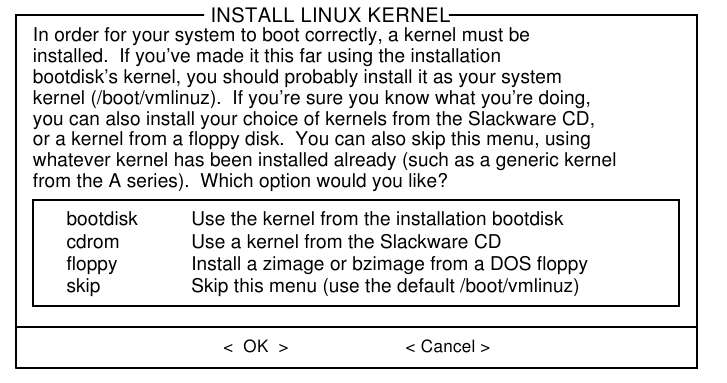
3.4.8.1 Selección del Núcleo
Aquí se le preguntará que núcleo instalar. Usted puede instalar el núcleo que se encuentra en el disquete de inicio que utilizó para instalar, desde el CD-ROM de Slackware, o desde otro disquete que usted (siempre con vista larga) haya preparado. O puede seleccionar "skip", en cuyo caso el núcleo predeterminado será instalado.
3.4.8.2 Hacer un disco de arranque
Hacer un disco de arranque para uso futuro es probablemente una buena idea. Usted tendrá la opción de formatear un disquete y crear uno o dos tipos de disquetes de inicio. El primer tipo, simple, simplemente (vaya a la figura) escribe el núcleo en el disquete. Una opción más flexible (y altamente recomendada) es la opción lilo, la cual, por supuesto, va a crear un disco de arranque con lilo. Ver LILO en la Sección 7.1 para obtener más información. Por supuesto, usted puede escoger sencillamente continue, en cuyo caso no se creará ningún disco de arranque.

3.4.8.3 Modem
Se le solicitará información sobre el modem. Más específicamente, se le preguntará si tiene un modem, y si lo tiene, en qué puerto serie se encuentra.

3.4.8.4 Zona Horaria
Esto es algo casi obvio: se le preguntará en que zona horaria usted se encuentra. Si usted opera en Zulú, lo sentimos mucho; la lista (extremadamente larga) está ordenada alfabéticamente, y usted queda al final.

3.4.8.5 Ratón
Esta subsección simplemente pregunta que tipo de ratón usted tiene, y si desea utilizarlo en la consola al iniciar, mediante gpm(8).

3.4.8.6 El Reloj de Hardware
Esta subsección pregunta si el reloj de hardware está puesto en hora con el Tiempo Universal Coordinado (UTC or GMT). La mayor parte de las PCs no lo están, así que probablemente debe decir no.

3.4.8.7 Fuente
La subsección de fuentes le permite seleccionar una desde una lista de fuentes personalizadas para la consola.

3.4.8.8 LILO
Aquí se le pregunta para la instalación de LILO (el LInux LOader; ver Sección 7.1 para más información).

Si Slackware va a ser el único sistema operativo en su computadora, simple debe funcionar bien para usted. Si usted está preparando un inicio dual, la opción expert es mejor. Vea la Sección 7.3 para más información sobre inicio dual. La tercera opción, do not install (no instalar), no es recomendada a menos que usted sepa lo que está haciendo y tenga una muy buena razón para no instalar LILO. Si usted está haciendo una instalación experta, se le dará la opción de donde poner el LILO. Usted puede poner el LILO en el MBR (Master Boot Record) de su disco duro, en el superbloque de su partición raíz de Linux, o en un disquete.
3.4.8.9 Red
La configuración de red es realmente netconfig. Ver la Sección 5.1 para mayor información.
3.4.8.10 Gestor X Window
Esta subsección le permitirá seleccionar el gestor de ventanas predeterminado para X. Vea el Capítulo 6 para obtener más detalles sobre X y los gestores de ventanas.

Capítulo 4 Configuración del Sistema
4.1 Panorámica del Sistema
Es importante entender como se estructura un sistema Linux antes de sumergirnos en los diferentes aspectos de su configuración. Un sistema Linux es significativamente diferente de uno DOS, Windows, o Macintosh (con la excepción de Mac OS X, basado en Unix), pero estas secciones le ayudarán a ponerse al corriente con su organización, de manera que usted pueda configurar fácilmente su sistema para que adapte a sus necesidades.
4.1.1 Organización del Sistema de Archivos
La primera diferencia notable entre Slackware Linux y DOS o Windows es el sistema de archivos. Para los principiantes, nosotros no utilizamos letras de unidades para denotar las diferentes particiones. En Linux existe un directorio principal. Usted puede relacionarla con la unidad C: bajo DOS. Cada partición en su sistema es montada en un directorio dentro del directorio principal. Es algo así como un disco duro siempre en expansión.
Le llamamos directorio principal al directorio raíz, y se denota con una barra sencilla (/). Este concepto puede parecer extraño, pero realmente hace la vida más fácil cuando usted desea adicionar más espacio. Por ejemplo, digamos que se le está terminando el espacio en la torre en la cual se encuentra /home. La mayoría de las personas instalan Slackware y hacen una gran torre raíz. Bien, teniendo en cuenta que una partición puede ser montada en cualquier directorio, usted simplemente va a la tienda, y busca un nuevo disco duro, y lo monta en /home. Ahora tiene un espacio más en su sistema. Y todo esto sin tener que mover mucho las cosas.
Debajo, hallará las descripciones de los directorios de nivel superior que existen en Slackware.
- bin
-
Los programas de usuario esenciales se almacenan aquí. Estos son, esencialmente, el grupo mínimo de programas que un usuario requiere para usar el sistema. Cosas como la consola y los comandos del sistema de archivos (ls, cp, y otros) se almacenan aquí. El directorio /bin usualmente no recibe modificaciones después de la instalación. Si sucedieran, sería en forma de paquetes que nosotros brindamos.
- boot
-
Los archivos que son utilizados por el cargador de Linux (LILO). Este directorio también recibe pocas modificaciones después de la instalación. El núcleo se almacena aquí desde Slackware 8.1. En versiones anteriores de Slackware, el núcleo estaba simplemente almacenado bajo / , pero como la práctica común es poner el núcleo y los archivos relacionados aquí para facilitar el inicio dual.
- dev
-
Todo en Linux es tratado como un archivo, incluso los dispositivos de hardware como los puertos series, discos duros, y escáneres. Para acceder a estos dispositivos, un archivo especial llamado nodo de dispositivo tiene que estar presente. Todos los nodos de dispositivos se almacenan en el directorio /dev. Usted verá que esto es así en muchos sistemas operativos al estilo Unix.
- etc
-
Este directorio almacena los archivos de configuración del sistema. Todo desde el archivo de configuración de X Window, la base de datos de usuarios, los scripts de inicio del sistema. El administrador del sistema se hará muy familiar con este directorio con el decursar del tiempo.
- home
-
Linux es un sistema operativo multiusuario. Cada usuario en el sistema tiene una cuenta y un directorio único para sus archivos personales. Este directorio es llamado el "home" de cada usuario. El directorio /home se brinda como la localización predeterminada para los directorios de los usuarios.
- lib
-
Las bibliotecas del sistema que se requieren para la operación básica se almacenan aquí. Las bibliotecas C, el cargador dinámico, la biblioteca ncurses, y los módulos del núcleo están entre las cosas que se almacenan aquí.
- mnt
-
Este directorio contiene puntos de montaje temporales para el trabajo con discos duros o unidades removibles. Aquí encontrará puntos de montaje para sus CD-ROM y sus disquetes.
- opt
-
Paquetes de software opcionales. La idea detrás de /opt es que cada paquete de software se instale en /opt/software-package, lo cual hace más sencillo eliminarlos más adelante. Slackware distribuye algunas cosas en /opt (como por ejemplo KDE en /opt/kde), pero usted es libre de adicionar lo que desee a /opt.
- proc
-
Este es un directorio único. Realmente, no es parte del sistema de archivos; es un sistema de archivos virtual que brinda acceso a la información del núcleo. Varias partes de la información que el núcleo desea que usted conozca se le muestra a usted a través del directorio /proc. Usted puede también enviar información al núcleo a través de algunos de estos archivos. Pruebe haciendo cat /proc/cpuinfo.
- root
-
El administrador del sistema es conocido como root en el sistema. El "home" de root se mantiene en /root en vez de en /home/root. La razón es simple. ¿Qué sucedería si /home estuviera en una partición diferente de / y no pudiera montarse? root naturalmente desearía entrar y reparar el problema. Si su directorio "home" estuviese en el sistema de archivos dañado, le sería muy difícil entrar.
- sbin
-
Programas esenciales que corre root y los que corren durante el proceso de inicio del sistema se almacenan aquí. Los usuarios comunes no pueden correr los programas de este directorio.
- tmp
-
La localización de almacenamiento temporal. Todos los usuarios tienen derechos de lectura y escritura en este directorio.
- usr
-
Este es el gran directorio en un sistema Linux. Todo lo demás va aquí, programas, documentación, el código fuente del núcleo, y el sistema X Window. Este es el directorio en el cual es más probable que usted esté instalando programas.
- var
-
Los archivos de registro (logs) del sistema, datos de cache, y archivos de claves de programas se almacenan aquí. Este es el directorio para los datos que cambian frecuentemente.
Ahora usted debe tener un buen sentido de qué contiene cada directorio en el sistema de archivos. Más información detallada sobre la organización del sistema de archivos está disponible en la página man de hier(7). La próxima sección debe ayudarlo a hallar archivos específicos fácilmente, de manera que no tenga que hacerlo a mano.
4.1.2 Buscando Archivos
Usted conoce a grandes rasgos qué contiene cada directorio, pero esto aún no lo ayuda realmente a encontrar las cosas. Es decir, usted puede ir mirando a través de los directorios, pero hay maneras más rápidas. Hay cuatro comandos principales de búsqueda disponibles en Slackware.
4.1.2.1 which
El primero es el comando which(1). which es utilizado para localizar un programa rápidamente. Este solo busca en su PATH y devuelve la primera instancia que encuentre y el camino del directorio hasta esta. Sirva este ejemplo:
% which bash |
Como puede ver, bash está en el directorio /bin. Este es un comando muy limitado para buscar, pues solo busca en su PATH.
4.1.2.2 whereis
El comando whereis(1) funciona de manera similar a which, pero puede buscar además en las páginas man y los archivos de fuentes. Una búsqueda de bash con whereis debe devolver esto:
% whereis bash |
Este comando no solo nos dice donde se encuentra el programa actual, sino donde está la documentación en línea almacenada. Aún así, el comando es limitado. ¿Y si usted deseara buscar un archivo de configuración específico? Usted no podría utilizar which o whereis para esto.
4.1.2.3 find
El comando find(1) le permite al usuario buscar en el sistema de archivos con una rica colección de predicados de búsqueda. Los usuarios pueden especificar una búsqueda con determinados comodines, rangos de modificación u hora de creación, u otras propiedades avanzadas. Por ejemplo, para buscar el archivo predeterminado xinitrc en el sistema, el siguiente comando puede ser utilizado.
% find / -name xinitrc |
find se va a demorar un poco en correr, pues tiene que recorrer todo el árbol de directorios. Y si el comando se corre como usuario normal, van a mostrarse mensajes de permisos denegados en los directorios que solo root puede ver. Pero find encontrará nuestro archivo, y eso es bueno. Si solo pudiera ser un poquito más veloz...
4.1.2.4 slocate
El comando slocate(1) busca en todo el sistema de archivos, al igual que el comando find, pero busca en una base de datos en vez de en el sistema de archivos actual. Esta base de datos se actualiza cada mañana, así que la lista que se ofrece va a estar bastante fresca. Usted puede manualmente correr updatedb(1) para actualizar la base de datos de slocate (antes de correr updatedb a mano, usted debe primero hacer su para correrlo como el usuario root). Aquí hay un ejemplo de slocate en acción:
% slocate xinitrc # no tenemos que ir a la raíz |
Hemos obtenido más de lo que estábamos buscando, y además rápido. Con estos comandos, usted debe poder encontrar cualquier cosa que esté buscando en su sistema Linux.
4.1.3 El Directorio /etc/rc.d
Los archivos de inicialización se almacenan en el directorio /etc/rc.d. Slackware utiliza la organización al estilo BSD para sus ficheros de inicialización, a diferencia de los scripts de inicio al estilo Sistema V, los cuales tienden a hacer que los cambios de configuración sean más complicados sin utilizar un programa especialmente diseñado para este propósito. En los scripts init de BSD, cada nivel (runlevel) se encuentra en un solo script rc. En Sistema V, cada nivel tiene su propio directorio, cada uno con numerosos scripts de inicio. El estilo BSD brinda una estructura organizada que es fácil de mantener.
Existen diversas categorías para los archivos de inicialización. Estas son arranque del sistema, niveles, inicialización de la red, y compatibilidad con Sistema V. Como es tradición, uniremos todo lo demás en otra categoría.
4.1.3.1 Inicio del Sistema
El primer programa que corre bajo Slackware además del núcleo Linux es init(8). Este programa lee el archivo /etc/inittab(5) para averiguar como correr el sistema. Este corre el script /etc/rc.d/rc.S para preparar el sistema antes de ir al nivel deseado. El archivo rc.S habilita la memoria virtual, monta sus sistemas de archivos, limpia ciertos directorios de logs, inicializa dispositivos "Plug and Play", carga los módulos del núcleo, configura dispositivos PCMCIA, prepara los puertos serie, y corre los scripts de inicio Sistema V (si existen). Obviamente rc.S tiene mucho que hacer, pero hay algunos scripts en /etc/rc.d que rc.S llamará para completar su trabajo.
- rc.S
-
Este es el script de inicialización del sistema.
- rc.modules
-
Carga los módulos del núcleo. Cosas como su tarjeta de red, soporte PPP, y otras se cargan aquí. Si este script encuentra a rc.netdevice, lo correrá también.
- rc.pcmcia
-
Prueba y configura cualquier dispositivo PCMCIA que usted pueda tener en su sistema. Este es más útil para los usuarios de portátiles, que probablemente tengan un modem o una tarjeta de red PCMCIA.
- rc.serial
-
Configura su puerto serie corriendo los comandos setserial apropiados.
- rc.sysvinit
-
Busca scripts Sistema V para el nivel deseado y los corre. Esto se discute con mayor detalle más adelante.
4.1.3.2 Scripts de Inicialización de Niveles
Después de que la inicialización del sistema se completa, init se mueve a una inicialización de acuerdo con el nivel. Un nivel (runlevel) describe el estado en el cual su máquina va a estar corriendo. ¿Suena redundante? Bueno, el nivel le dice a init si usted va a estar aceptando varios usuarios, o uno solo, si desea utilizar servicios de red o no, y si va a estar utilizando el sistema X Window o agetty(8) para manejar los inicios de sesión. Los archivos a continuación definen los diferentes niveles en Slackware Linux.
- rc.0
-
Detiene el sistema (runlevel 0). Por omisión, está enlazado a rc.6.
- rc.4
-
Inicio multiusuario (runlevel 4) en X11 con KDM, GDM, o XDM como el gestor de inicio.
- rc.6
-
Reinicia el sistema (runlevel 6).
- rc.K
-
Inicio en modo usuario único (runlevel 1).
- rc.M
-
Modo multiusuario (runlevels 2 y 3), pero con el inicio de sesión estándar basado en texto. Este es el nivel por omisión en Slackware.
4.1.3.3 Inicialización de la Red
Los niveles 2, 3, y 4 van a arrancar los servicios de red. Los siguientes archivos son los responsables de la inicialización de red:
- rc.inet1
-
Creado por netconfig, este archivo es responsable de configurar la interfaz de red actual.
- rc.inet2
-
Corre después de rc.inet1 y arranca los servicios de red básicos.
- rc.atalk
-
Arranca los servicios AppleTalk.
- rc.httpd
-
Arranca el servidor web Apache. Como otros pocos scripts rc, este puede ser utilizado para detener y reiniciar el servicio. rc.httpd toma argumentos de parada, arranque y reinicio.
- rc.news
-
Arranca el servidor de noticias.
4.1.3.4 Compatibilidad Sistema V
La compatibilidad con Sistema V se introdujo en Slackware 7.0. Muchas otras distribuciones de Linux hacen uso de este estilo en vez del estilo BSD. Básicamente, cada nivel posee un directorio para los scripts de inicio, mientras que el estilo BSD brinda un script de instalación para cada nivel.
El script rc.sysvinit buscará cualquier script Sistema V que usted tenga en /etc/rc.d y lo correrá, si el nivel (runlevel) es apropiado. Esto es útil para ciertos paquetes de software comercial que instalan scripts al estilo Sistema V.
4.1.3.5 Otros Archivos
Los scripts descritos a continuación son los demás scripts de inicialización del sistema. Estos típicamente corren desde uno de los scripts mayores descritos arriba, de manera que lo único que usted necesita hacer es editar los contenidos.
- rc.gpm
-
Arranca los servicios del ratón para propósito general. Permite cortar y pegar en la consola de Linux. Ocasionalmente, gpm causará problemas con el ratón cuando se utiliza bajo ventanas X. Si usted experimenta problemas con el ratón bajo X, pruebe quitando los permisos de ejecución de este script y deteniendo el servidor gpm.
- rc.font
-
Carga la fuente personalizada para mostrar los caracteres en la consola.
- rc.local
-
Contiene cualquier comando específico de inicio para su sistema. Está vacío después de una nueva instalación, y está reservado para los administradores locales. Este script corre después que el resto de las inicializaciones han terminado.
Para habilitar un script, todo lo que necesita hacer es adicionar los permisos de ejecución a este con el comando chmod. Para deshabilitar un script, elimínele los permisos de ejecución. Para más información sobre chmod, vea la Sección 9.2.
4.2 Seleccionando un Núcleo
El núcleo es la parte del sistema operativo que brinda el acceso al hardware, el control de procesos, y el control total del sistema. El núcleo contiene soporte para sus dispositivos de hardware, de manera que la elección del núcleo para su sistema es un paso importante.
Slackware brinda más de una docena de núcleos precompilados, desde los cuales usted puede seleccionar, cada uno con un grupo estándar de controladores, y controladores específicos adicionales. Usted puede correr uno de los núcleos precompilados, o construir su propio núcleo desde las fuentes. De cualquier manera, usted necesita cerciorarse de que el núcleo tiene el soporte de hardware que su sistema necesita.
4.2.1 El Directorio /kernels en el CD-ROM de Slackware
Los núcleos precompilados de Slackware están disponibles en el directorio /kernels en el CD-ROM de Slackware o en el sitio FTP en el directorio principal de Slackware. Los núcleos disponibles cambian en la medida en que se realizan liberaciones (releases), así que la documentación en este directorio es siempre una fuente de autoridad. El directorio /kernels tiene subdirectorios para cada núcleo disponible. Los subdirectorios tienen el mismo nombre que su disco de inicio acompañante. En cada subdirectorio usted hallará los siguientes archivos:
4.2.2 Compilando un Núcleo desde el Código Fuente
La pregunta “¿Debo compilar un núcleo para mi sistema?” es escuchada frecuentemente en los nuevos usuarios. La respuesta es un quizás definitivo. Hay pocos ejemplos en los cuales usted necesita compilar un núcleo específico para su sistema. La mayoría de los usuarios pueden usar un núcleo precompilado y con los módulos cargables lograr un sistema totalmente funcional. Usted necesitará compilar un núcleo para su sistema si está actualizando a versiones del núcleo que en ese momento no se ofrezcan en Slackware, o usted ha parcheado el código del núcleo para brindar soporte a un dispositivo determinado que no está en el núcleo nativo. Cualquiera que tenga un sistema SMP definitivamente querrá compilar el núcleo con soporte SMP. Además, muchos usuarios encuentran que un núcleo compilado según sus necesidades corre mucho más rápido en su máquina. Usted puede encontrar útil compilar el núcleo con las optimizaciones disponibles para su procesador en específico.
Construir su propio núcleo no es tan difícil. El primer paso es asegurarse de que usted tiene las fuentes del núcleo instaladas en su sistema. Asegúrese de que usted instaló los paquetes de la serie K durante la instalación. Usted también querrá estar seguro de que usted tiene la serie D instalada, específicamente el compilador de C, GNU make, y GNU binutils. En general, es una buena idea tener la serie D completa instalada si usted planea hacer cualquier clase de desarrollo. Usted puede también descargar la última fuente del núcleo desde http://www.kernel.org/mirrors.
4.2.2.1 Compilación del Núcleo de Linux versión 2.4.x
% su - |
El primer paso es poner las fuentes del núcleo en su estado base. Emitimos este comando para hacer esto (usted puede que desee respaldar el archivo .config ya que este comando lo va a eliminar si preguntar):
# make mrproper
|
Ahora usted puede configurar el núcleo para su sistema. El núcleo actual ofrece tres vías para hacer esto. La primera es el sistema original, basado en texto, de preguntas y respuestas. Este hace muchas preguntas y construye un archivo de configuración. El problema con este método es que si usted comete una equivocación, debe comenzar de nuevo. El método que la mayoría prefiere es el dirigido mediante un menú. Últimamente, existe una herramienta para la configuración del núcleo basada en X. Seleccione el que desee y emita el comando apropiado:
# make config (versión basada en texto, preguntas y respuestas) |

# make dep |
El próximo paso es compilar el núcleo. Primero trate emitiendo el comando bzImage:
# make bzImage
|
# make modules
|
# mv /boot/vmlinuz /boot/vmlinuz.old |
4.2.2.2 Núcleo de Linux Versión 2.6.x
La compilación de un núcleo 2.6 es solo ligeramente diferente de un núcleo 2.4 o 2.2, pero es importante que usted entienda las diferencias antes de seguir introduciéndonos al tema. Ya no es necesario correr make dep ni make clean. Además, el proceso de compilación del núcleo ya no es tan extremadamente comunicativo en la serie 2.6. Esto resulta en un proceso de construcción más fácil de entender, pero que tiene limitaciones también. Si usted tiene problemas construyendo el núcleo, es altamente recomendado que usted restaure todo ese exceso de comunicación. Para hacer esto simplemente adicione V=1 a la construcción. Esto permite anotar más información que puede ayudar al desarrollador del núcleo o a otro geek sociable a resolver el asunto.
# make bzImage V=1
|
4.2.3 Usando los Módulos del Núcleo
Los módulos del núcleo son otro nombre para los controladores de dispositivos que pueden ser insertados en un núcleo corriendo. Ellos permiten extender el hardware soportado por su núcleo sin necesidad de seleccionar otro núcleo o compilar uno usted mismo.
Los módulos también pueden ser cargados y descargados en cualquier momento, incluso con el sistema corriendo. Esto hace que actualizar controladores específicos sea fácil para los administradores de sistema. Un nuevo módulo puede ser compilado, el antiguo eliminado, y el nuevo cargado, todo sin reiniciar la máquina.
Los módulos se almacenan en el directorio /lib/modules/kernel version en su sistema. Estos pueden ser cargados desde el inicio a través del archivo rc.modules. Este archivo está muy bien comentado y ofrece ejemplos para los mayores componentes de hardware. Para ver una lista de los módulos que están actualmente activos, use el comando lsmod(1):
# lsmod |
Usted puede ver aquí que yo solo tengo cargado el módulo para el puerto paralelo. Para eliminar un módulo, usted debe usar el comando rmmod(1). Los módulos pueden ser cargados con los comandos modprobe(1) o insmod(1). modprobe es usualmente más seguro, puesto que va a cargar todos los módulos de los cuales el que usted está tratando de instalar depende.
Muchos usuarios nunca han tenido que cargar o descargar un módulo a mando. Ellos utilizan el autocargador del núcleo para la gestión de los módulos. Por omisión, Slackware incluye kmod en sus núcleos. kmod es una opción del núcleo que habilita al núcleo para que automáticamente cargue los módulos en la medida en que son solicitados. Para más información sobre kmod y como se configura, vea /usr/src/linux/Documentation/kmod.txt. Usted necesitará tener instalado el paquete de fuentes del núcleo, o descargar las fuentes del núcleo desde http://kernel.org.
Más información puede ser encontrada en las páginas man para cada uno de estos comandos, más en el archivo rc.modules.
Capítulo 5 Configuración de Red
5.1 Introducción: netconfig es su amigo.
Cuando usted inicialmente instaló Slackware, el programa de instalación invocó al programa netconfig. netconfig intenta realizar las siguientes funciones para usted:
-
Le pregunta por el nombre de su computadora, y el nombre de dominio de su computadora.
-
Le da una breve explicación de los distintos esquemas de direccionamiento, cuando deben ser usados, y pregunta que esquema de direccionamiento IP usted desea utilizar para configurar su tarjeta de red:
-
IP Estático
-
DHCP
-
Bucle (loopback)
-
-
Entonces le ofrece sondear para hallar una tarjeta de red que configurar
netconfig generalmente se ocupará del 80% del trabajo de configurar su LAN si se lo permite. Note que le recomiendo fuertemente que revise su archivo de configuración por un par de razones:
-
Usted nunca debe confiar en que un programa de instalación configure correctamente su computadora. Si usted usa un programa de instalación, usted debe revisar la configuración personalmente.
-
Si usted aún está aprendiendo Slackware y gestión de sistemas Linux, ver una configuración que funcione puede ser útil. Usted al menos sabrá a qué se parece una configuración. Esto le va a permitir corregir problemas debido a configuraciones erróneas del sistema posteriormente.
5.2 Configuración del Hardware de Red
Habiendo decidido que usted desea conectar su máquina Slackware en alguna clase de red, la primera cosa que usted necesitará es una tarjeta de red compatible con Linux. Usted debe tener un mínimo de cuidado para asegurarse que la tarjeta es verdaderamente compatible con Linux (por favor, refiérase al Proyecto de Documentación de Linux y/o la documentación del núcleo para obtener información sobre el estado actual de la tarjeta de red propuesta). Por regla general, usted deberá estar placenteramente sorprendido por el número de tarjetas de red que se soportan bajo los núcleos más modernos. Dicho esto, aún le recomiendo referirse a cualquiera de las listas de compatibilidad de hardware (por ejemplo The GNU/Linux Beginners Group Hardware Compatibility Links y The Linux Documentation Project Hardware HOWTO) que están disponibles en Internet antes de comprar su tarjeta. Un poco de tiempo extra pasado en la investigación puede ahorrarle días e incluso semanas tratando de solucionar el problema de su tarjeta, que para nada es compatible con Linux.
Cuando usted visite las listas de Compatibilidad de Hardware de Linux disponibles en Internet, o cuando se refiera a la documentación del núcleo instalada en su máquina, es importante notar que módulo del núcleo usted necesitará usar para soportar su tarjeta de red.
5.2.1 Cargando los Módulos de Red
Los módulos del núcleo que se cargan al arrancar el sistema, se cargan desde el archivo rc.modules en /etc/rc.d o por el autocargador de módulos del núcleo, iniciado por /etc/rc.d/rc.hotplug. El archivo rc.modules por omisión incluye una sección de soporte a dispositivos de red. Si usted abre rc.modules y busca esta sección, usted verá que esta primero busca un archivo ejecutable llamado rc.netdevice en /etc/rc.d/. Este script es creado si setup autodetecta su dispositivo de red durante la instalación.
Debajo de ese bloque “if” hay una lista de dispositivos de red y líneas de modprobe, cada una comentada. Busque su dispositivo, descomente la línea modprobe correspondiente, y salve el archivo. Corriendo rc.modules como root debe ahora cargar su controlador de dispositivo de red (así como otros módulos que están listados y descomentados). Note que algunos módulos (como el controlador ne2000) requieren parámetros; asegúrese de que usted seleccione la línea correcta.
5.2.2 Tarjetas LAN (10/100/1000Base-T y Base-2)
Este encabezamiento incluye todas las tarjetas de red internas PCI e ISA. Los controladores para estas tarjetas se brindan vía módulos cargables del núcleo, como se describió en el párrafo anterior. /sbin/netconfig debe haber detectado su tarjeta de red, y haber configurado exitosamente su archivo rc.netdevice. Si esto no ocurre, el problema más común debe ser que el módulo que usted está intentando cargar para una tarjeta dada es incorrecto (es conocido que para diferentes generaciones de la misma marca de tarjetas del mismo fabricante pueden ser requeridos diferentes módulos). Si usted está seguro de que el módulo que usted está intentando cargar es el correcto, su próxima parada debe ser referirse a la documentación del módulo, para intentar descubrir cuando se requieren parámetros específicos durante la inicialización de este.
5.2.3 Modems
Como las tarjetas LAN, los modems pueden venir con diferentes opciones de soporte para el bus. Hasta hace poco, la mayoría de los modems eran tarjetas ISA de 8 o 16 bits. Con los esfuerzos de Intel y los fabricantes de placas base de todas partes puestos en función de destruir completamente al bus ISA, es común ahora encontrar que la mayoría de los modems son o bien modems externos que se conectan al puerto serie o USB o son modems internos PCI. Si usted desea que su modem funcione con Linux, es VITAL que investigue su modem prospecto a compra, particularmente si usted está comprando un modem PCI. Muchos, por no decir la mayoría de los modems PCI disponibles en tiendas por estos días son WinModems. Los WinModems carecen de algún hardware básico en la tarjeta del modem: Las funciones que realiza este hardware es típicamente descargada a la CPU por los controladores del modem y el sistema operativo Windows. Esto significa que no poseen la interfaz serie estándar que PPPD espera ver cuando usted intenta marcar hacia su Proveedor de Servicios de Internet.
Si usted desea estar absolutamente seguro de que el modem que usted está comprando trabajará con Linux, compre un modem externo que se conecte al puerto serie de su PC. Estos están garantizados que funcionan mejor y dan menos problemas para instalar y mantener, aunque requieren una fuente externa, y tienden a costar más.
Existen muchos sitios web que brindan controladores y asistencia para configurar dispositivos basados en WinModems. Algunos usuarios han reportado configuraciones e instalaciones exitosas con varios winmodems, incluyendo chipsets Lucent, Conexant, y Rockwell. Como el software requerido para estos dispositivos no está incluido en Slackware, y varía de un controlador a otro, no vamos a caer en detalles.
5.2.4 PCMCIA
Como parte de su instalación Slackware, se le brinda la oportunidad de instalar el paquete pcmcia (en la serie “A” de paquetes). Este paquete contiene las aplicaciones y los archivos de configuración que se requieren para trabajar con tarjetas PCMCIA bajo Slackware. Es importante notar que el paquete pcmcia solo instala software genérico requerido para trabajar con tarjetas PCMCIA bajo Slackware. Este NO instala controladores ni módulos. Los módulos disponibles estarán en el directorio /lib/modules/`uname -r`/pcmcia. usted puede necesitar hacer algunos experimentos para hallar el módulo que trabaja con su tarjeta de red.
Usted necesitará editar /etc/pcmcia/network.opts (para una tarjeta Ethernet) o /etc/pcmcia/wireless.opts (si usted posee una tarjeta de red inalámbrica). Como la mayoría de los archivos de configuración de Slackware, estos dos archivos están bien comentados, y debe ser fácil determinar las modificaciones que se necesiten hacer.
5.3 Configuración TCP/IP
En este punto, su tarjeta de red debe estar instalada físicamente en su computadora, y los módulos del núcleo necesarios deben estar cargados. Usted no debe aún poder comunicarse mediante su tarjeta de red, pero información sobre el dispositivo de red puede obtenerse con ifconfig -a.
# ifconfig -a |
Si usted solo teclea /sbin/ifconfig sin el sufijo -a, usted no verá la interfaz eth0, pues su tarjeta de red aún no tiene dirección IP válida ni ruta.
Aunque hay diversas maneras de configurar y poner subredes a las redes, todas ellas pueden ser separadas en dos tipos: Estáticas y Dinámicas. Las redes estáticas se configuran de manera que cada nodo (jerga geek para nombrar cualquier cosa con dirección IP) siempre tengan la misma dirección IP. Las redes dinámicas se configuran de manera que las direcciones IP de los nodos se controlan por un solo servidor llamado servidor DHCP.
5.3.1 DHCP
DHCP (o Dynamic Host Configuration Protocol - Protocolo de Configuración Dinámica de Host), es el medio a través del cual las direcciones IP pueden ser asignados a una computadora al arrancar. Cuando el cliente DHCP arranca, pone una solicitud de la Red de Area Local (LAN) para el servidor DHCP, para que le asigne una dirección IP. El servidor DHCP tiene un fondo de direcciones IP disponibles. El servidor va a responder a esta solicitud con una dirección IP del fondo, junto con un tiempo de arrendamiento. Una vez que el tiempo de arrendamiento para una dirección IP dada haya expirado, el cliente debe contactar al servidor de nuevo y repetir la negociación.
El cliente entonces aceptará la dirección IP que le brinda el servidor y configurará la interfaz de red que lo solicitó con la dirección IP. Existe además un truquito que el cliente DHCP usa para la negociación de la dirección IP que le deben asignar. El cliente recordará su última dirección IP, y va a solicitarle al servidor que se la reasigne, hasta la próxima negociación. Si es posible, el servidor lo hará, pero si no, se le asignará una nueva dirección. De manera que la negociación sería algo así:
Cliente:
¿Hay algún
servidor DHCP disponible en la LAN?
Servidor:
Si, hay uno. Aquí estoy.
Cliente:
Necesito una dirección IP.
Servidor:
Puedes tomar 192.168.10.10
por 19200 segundos.
Cliente:
Gracias.
Cliente: ¿Hay
algún
servidor DHCP disponible en la LAN?
Servidor:
Si, hay uno. Aquí estoy.
Cliente:
Necesito una dirección IP. La última vez que
hablamos,
yo
tenía 192.168.10.10;
¿Puedo tenerla de nuevo?
Servidor:
Si, puedes (o No, no
puedes: toma 192.168.10.12 en
cambio).
Cliente:
Gracias.
El cliente DHCP en Linux es /sbin/dhcpcd. Si usted carga /etc/rc.d/rc.inet1 en su editor de texto favorito, usted notará que /sbin/dhcpcd es llamado a medio camino del script. Esto va a forzar la conversación mostrada anteriormente. dhcpcd también va a mantener la cuenta del tiempo que queda de arrendamiento de la dirección IP actual, y va a contactar automáticamente al servidor DHCP con una solicitud para renovar el arrendamiento cuando sea necesario. DHCP puede además controlar información relacionada, como que servidor ntp usar, que ruta tomar, etc.
Configurar DHCP en Slackware es simple. Solo corra netconfig y seleccione DHCP cuando se le ofrezca. Si usted tiene más de una tarjeta de red, y no desea que eth0 sea configurada por DHCP, solo edite el archivo /etc/rc.d/rc.inet1.conf y cambie la variable relacionada con su interfaz de red a “YES”.
5.3.2 IP Estático
Las direcciones IP estáticas son direcciones fijas que solo cambian cuando se modifican manualmente. Estas se utilizan cuando el administrador no desea que la información IP cambie, ya sea en servidores internos de una LAN, cualquier servidor conectado a Internet, y enrutadores en red. Con direcciones IP estáticas, usted asigna una dirección y así la deja. Otras máquinas conocen que usted siempre radica en esa dirección IP, y pueden contactarlo ahí siempre.
5.3.3 /etc/rc.d/rc.inet1.conf
Si usted planea asignar una dirección IP a su nuevo Slackware, puede hacerlo a través del script netconfig, o editando /etc/rc.d/rc.inet1.conf. En /etc/rc.d/rc.inet1.conf , usted verá:
# Primary network interface card (eth0) |
Entonces al final:
GATEWAY="" |
En este caso, nuestra tarea es meramente poner la información correcta entre las comillas. Estas variables son llamadas por /etc/rc.d/rc.inet1 al inicio para configurar las interfaces de red (NIC). Para cada NIC, simplemente entre la información IP correcta, o ponga “YES” en USE_DHCP para habilitar el DHCP. Slackware va a iniciar las interfaces con la información que se ponga aquí, en el orden que aparezca.
La variable DEFAULT_GW fija la ruta por omisión para Slackware. Todas las comunicaciones entre su computadora y otras computadoras en Internet debe pasar a través de esta pasarela, si no se especifica otra ruta para ellas. Si usted está usando DHCP, usted normalmente no necesita poner nada aquí, puesto que el servidor DHCP le especificará que pasarela utilizar.
5.3.4 /etc/resolv.conf
Bien, ya usted tiene una dirección IP, ya tiene una pasarela por omisión, incluso puede tener diez millones de dólares (denos algo), pero ¿cuan bueno puede ser eso si no puede resolver las direcciones IP de los nombres? Nadie quiere teclear 72.9.234.112 en su explorador web para alcanzar www.slackbook.org. Después de todo, ¿quién además de los autores desearía memorizar esa dirección IP? Necesitamos configurar DNS, ¿Pero cómo? Es aquí cuando /etc/resolv.conf entra en el juego.
Es posible que usted ya tenga de antemano las opciones correctas en /etc/resolv.conf. Si usted configuró su conexión de red utilizando DHCP, el servidor DHCP debe haber actualizado este archivo por usted. (Técnicamente el servidor DHCP solo le dice a dhcpcd que debe poner ahí, y este obedece.) Si usted necesita actualizar manualmente su lista de DNS, necesita editar /etc/resolv.conf. Debajo hay un ejemplo:
# cat /etc/resolv.conf |
La primera línea es simple. La directiva nameserver dice que servidores DNS consultar. Por necesidad estas son siempre direcciones IP. Usted puede tener tantas en lista como desee. Slackware va a chequear felizmente uno tras otro hasta que uno reporte coincidencia.
La segunda línea es un poco más interesante. La directiva search nos brinda una lista de nombres de dominio para asumir siempre que se hace una solicitud al DNS. Esto permite contactar una máquina con solo la primera parte de su FQDN (Fully Qualified Domain Name- Nombre de Dominio Totalmente Calificado). Por ejemplo, si “slackware.com” estuviese en su camino de búsqueda, usted pudiera alcanzar http://store.slackware.com solamente apuntando su explorador web a http://store.
# ping -c 1 store |
5.3.5 /etc/hosts
Ahora que tenemos DNS funcionando bien, ¿que sucede si queremos circunvalar a nuestro DNS, o adicionar una entrada al DNS para una máquina que no está en el DNS? Slackware incluye el archivo tan querido /etc/hosts, el cual contiene una lista local de nombres de DNS y direcciones IP que debe hacer concordar.
# cat /etc/hosts |
Aquí usted puede ver que localhost (su propia máquina) tiene una dirección IP 127.0.0.1 (siempre reservada para localhost), redtail puede ser alcanzada en 192.168.1.101, y foobar.slackware.com es 172.14.66.32.
5.4 PPP
Mucha gente aún se conecta a Internet a través de algún tipo de conexión de marcado (dialup). El método más común es PPP, aunque SLIP aun se utiliza en ocasiones. Configurar su sistema para que hable PPP con un servidor remoto es muy sencillo. Hemos incluido unas cuantas herramientas para ayudarlo a configurarlo.
5.4.1 pppsetup
Slackware incluye un programa llamado pppsetup para configurar su sistema para utilizar su cuenta de marcado. Este comparte su apariencia con nuestro programa netconfig. Para correr el programa, asegúrese de que está en una sesión como root. Entonces teclee pppsetup para correrlo. Usted debe ver una pantalla como esta:
El programa va a presentar una serie de preguntas, a la cual usted debe responder con las respuestas apropiadas. Cosas como su dispositivo de modem, la cadena de inicialización del modem, y el teléfono del ISP (Internet Service Provider - Proveedor de Servicios de Internet) Algunos pasos tienen configuraciones por omisión, las cuales puede aceptar en la mayoría de los casos.
Después de que el programa corre, este va a crear un programa ppp-go y un programa ppp-off. Estos se utilizan para arrancar y parar, respectivamente, la conexión PPP. Los dos programas se localizan en /usr/sbin y necesitan privilegios de root para correr.
5.4.2 /etc/ppp
Para la mayoría delos usuarios, correr pppsetup será suficiente. De todas formas, puede suceder que usted necesite hacer pequeños cambios los valores usados por el demonio PPP. Toda la información de configuración se guarda en /etc/ppp. Aquí hay una lista de para que sirven los diferentes archivos:
| ip-down |
Este script es corrido por pppd después que la conexión PPP finalizó. |
| ip-up |
Este script es corrido por pppd cuando hay una conexión ppp exitosa. Ponga aquí cualquier comando que usted desee correr después de una conexión exitosa. |
| options |
Opciones generales de configuración para pppd. |
| options.demand |
Opciones generales de configuración para pppd cuando corre en modo de marcado en demanda |
| pppscript |
Los comandos mandados al modem. |
| pppsetup.txt |
Una bitácora de lo que usted tecleó cuando corrió pppsetup. |
 |
La mayor parte de estos archivos no estarán ahí hasta después que corra pppsetup. |
5.5 Wireless
Las redes wireless (inalámbricas) aún son una cosa relativamente nueva en el mundo de las computadoras, aunque está captando muchas personas que compran laptops y quieren que la red funcione, sin tener que andar buscando un viejo cable par trenzado. Esta tendencia no parece decrecer. Desafortunadamente, las redes inalámbricas no están aún fuertemente soportadas en Linux, en comparación con las redes tradicionales alambradas.
Existen tres pasos básicos para configurar una tarjeta inalámbrica Ethernet 802.11:
-
Soportar el hardware para la tarjeta inalámbrica
-
Configurar la tarjeta para conectarse a un punto de acceso inalámbrico
-
Configurar la red
5.5.1 Soporte de Hardware
El soporte de hardware para una tarjeta inalámbrica se brinda a través del núcleo, bien con un módulo o construyendo el núcleo con el soporte incluido. Generalmente, las tarjetas Ethernet más nuevas se proveen mediante un módulo del núcleo, de manera que usted necesita determinar en qué módulo está, y habilitarlo en /etc/rc.d/rc.modules. netconfig, aunque esto puede no detectarlo automáticamente, así que probablemente usted necesite deteminarlo personalmente. Vea http://www.hpl.hp.com/personal/Jean_Tourrilhes/Linux/ para obtener mayor información sobre los controladores del núcleo para las diferentes tarjetas inalámbricas.
5.5.2 Configurar las Opciones Wireless
La gran mayoría de este trabajo se realiza a través de iwconfig, así que como siempre, lea la página man para iwconfig si necesita más información.
Primero, usted debe configurar su punto de acceso inalámbrico. Los puntos de acceso inalámbricos varían un poco en su terminología, y en cómo configurarlos, así que usted necesitará ajustar un poco para acomodarse a su hardware. En general, usted necesitará al menos la siguiente información:
-
El identificador de dominio (domain ID), o nombre de la red (llamado ESSID por iwconfig)
-
El canal que utiliza el WAP.
-
La configuración de encriptación, incluyendo todas las llaves que se utilizan (preferentemente en hexadecimal)
|
UNA NOTA SOBRE WEP. WEP es bastante defectuoso, pero es mejor que nada. Si usted desea un mayor grado de seguridad en su red inalámbrica, usted debe investigar VPNs o IPSecs, ambos fuera del alcance de este documento. Usted debe además configurar su WAP de no advertir su ID/ESSID de dominio. Una discusión más profunda de las políticas inalámbricas está más allá del alcance de esta sección, pero una búsqueda rápida en Google le va a revelar más de lo que usted hubiese deseado saber. |
Una vez que usted haya recopilado la información anterior, y asumiendo que usted haya utilizado modprobe para cargar el controlador apropiado del núcleo, usted puede editar rc.wireless.conf y poner ahí sus configuraciones. El archivo rc.wireless.conf es un poco desaliñado. El menor esfuerzo es modificar la sección genérica con su ESSID y KEY (llave), y el canal (CHANNEL) si es requerido por su tarjeta. (Pruebe no poner CHANNEL, y si funciona, perfecto; si no, ponga CHANNEL como sea apropiado.) Si usted es atrevido, puede modificar el archivo de manera que solo queden puestas las variables necesarias. Los nombres de variables en rc.wireless.conf corresponden a los parámetros de iwconfig, y son leídos por rc.wireless y utilizados en los comandos iwconfig apropiados.
Si usted tiene su llave en hexadecimal, es ideal, así que usted puede estar justamente convencido de que su WAP y iwconfig van a estar de acuerdo en la llave. Si usted solo tiene una cadena, usted no puede estar seguro de como su WAP la va a traducir a hexadecimal, de manera que va a tener que hacer todo un trabajo de adivinación (u obtener la llave de su WAP en hexadecimal).
Una vez que usted haya modificado rc.wireless.conf, corra rc.wireless como root, y entonces corra rc.inet1, una vez más como root. Usted puede probar su red inalámbrica con las herramientas habituales de prueba, como ping, sobre iwconfig. Si usted tiene una interfaz alambrada, entonces probablemente necesite utilizar ifconfig para apagar el resto de las interfaces mientras usted prueba su tarjeta para asegurarse de que no hay interferencia. También puede desear probar sus cambios a través del reinicio de la máquina.
Ahora que usted ha visto como editar /etc/rc.d/rc.wireless para su red por omisión, vamos a mirar más de cerca a iwconfig para ver como funciona. Esto le va a enseñar una manera rápida y sucia de configurar wifi en aquellos casos en los cuales usted se encuentra en un Internet café, cafetería, o cualquier otro hot spot wifi y desea estar en línea.
El primer paso es decirle a su interfaz de red inalámbrica a que red unirse. Asegúrese de reemplazar “eth0” con el número que utiliza su interfaz de red y cambie “mynetwork” con el essid que usted desee utilizar. Si, sabemos que usted es más inteligente que ella. Lo próximo que usted debe especificar es la llave de encriptación (si existe) que se utiliza en su red inalámbrica. Finalmente especifique el canal que utilizar (si es necesario).
# iwconfig eth0 essid "mynetwork" |
Esto debe ser todo, al final, cuando quieres utilizar una red inalámbrica.
5.5.3 Configurar la Red
Esto se realiza exactamente de la misma forma que con las redes alambradas. Simplemente refiérase a las secciones anteriores de este capítulo.
5.6 Sistemas de Archivos en Red
Llegado este punto, usted debe tener una conexión TCP/IP que funcione en su red. Usted debe poder hacerle ping a otras computadoras en su red, y si configuró una pasarela adecuada, incluso debe poder hacerle ping a computadoras conectadas a Internet. Como sabemos, el todo de conectar una computadora a una red es acceder a la información. Aunque algunas personas puede que deseen conectarse solo por el placer de hacerlo, la mayoría desean poder compartir archivos e impresoras. Desean poder acceder a documentos en Internet o jugar juegos en línea. Teniendo TCP/IP instalado y funcionando en su nuevo sistema Slackware es un medio para esos fines, pero solamente con TCP/IP instalado, las funcionalidades son muy rudimentarias. Para compartir archivos, tendremos que transferirlos de un lado a otro con FTP o SCP. No podremos explorar archivos en nuestra nueva computadora Slackware desde los íconos de Vecindario de Red o Mis Sitios de Red en computadoras Windows. Puede que deseemos, además, acceder archivos en otras máquinas Unix transparentemente.
Idealmente, nos gustaría usar un sistema de archivos en red que nos permita acceso transparente a nuestros archivos en otras computadoras. Los programas que utilizaremos para interactuar con la información almacenada en nuestras computadoras realmente no necesitan saber en qué computadora está almacenado un archivo dado; solamente necesitan saber si existe y como llegar a él. Es responsabilidad del sistema operativo gestionar el acceso hacia ese archivo a través de los sistemas de archivos disponibles, y de los sistemas de archivos de red. Los dos sistemas de archivos de red más comúnmente utilizados son SMB (implementado por Samba) y NFS.
5.6.1 SMB/Samba/CIFS
SMB (siglas de Server Message Block) es un descendiente del viejo protocolo NetBIOS que fue inicialmente utilizado por IBM en su producto LAN Manager. Microsoft siempre ha estado muy interesada en NetBIOS y sus sucesores (NetBEUI, SMB y CIFS). El proyecto Samba ha existido desde 1991, cuando fue escrito originalmente para enlazar una IBM PC corriendo NetBIOS con un servidor Unix. Por estos días, SMB es el método preferido para compartir archivos e impresoras en red por casi todo el mundo, pues Windows le brinda soporte.
El archivo de configuración de Samba es /etc/samba/smb.conf; uno de los archivos de configuración mejor comentados y documentados que usted encontrará jamás. En él existen ejemplos de como compartir, para que usted los modifique de acuerdo a sus necesidades. Si usted necesita un control más estricto, la página man de smb.conf es indispensable. Como Samba está tan bien documentado en los lugares anteriormente mencionados, no reescribiremos la documentación aquí, solamente nos limitaremos a cubrir, rápidamente, los aspectos básicos
smb.conf se divide en múltiples secciones: una sección por recurso compartido, y una sección global para las opciones que se utilizan de manera general. Algunas opciones solamente son válidas en la sección global, otras solamente fuera de la sección global. Recuerde que la sección global puede ser derogada por cualquier otra sección. Refiérase a las páginas man para obtener más información.
Lo más probable es que usted desee editar su archivo smb.conf para que refleje la configuración de red de su LAN. Mi sugerencia es que modifique los apartados siguientes:
[global] |
Cambie el grupo de trabajo (workgroup) para que refleje el grupo de trabajo o el nombre de dominio que se utilice localmente.
# server string is the equivalent of the NT Description field |
Este debe ser el nombre de la computadora Slackware cuando aparezca en la carpeta Vecindario de Red (o Mis Sitios de Red).
# Security mode. Most people will want user level security. See |
Casi seguramente usted deseará implementar seguridad a nivel de usuario en su sistema Slackware.
# You may wish to use password encryption. Please read |
Si la opción encriptar contraseñas (encrypt passwords) no se encuentra habilitada, usted no podrá usar Samba con NT4.0, Win2k, WinXP, y Win2003. Los sistemas operativos Windows anteriores no requieren encriptación para compartir archivos.
SMB es un protocolo con autenticación, lo cual significa que usted debe brindar un nombre de usuario y una contraseña correcta para poder usar este servicio. Le diremos al servidor Samba que nombres de usuarios y contraseñas son válidos con el comando smbpasswd. smbpasswd toma un par de modificadores comunes para decirle si adicionar usuarios tradicionales, o adicionar usuarios de máquina (SMB requiere que usted adicione los nombres de NETBIOS como usuarios de máquina, restringiendo desde qué computadora uno puede autenticarse).
Adding a user to the /etc/samba/private/smbpasswd file. |
Es importante notar que el nombre de usuario dado debe existir en el archivo /etc/passwd. Usted puede lograr esto simplemente con el comando adduser. Note que cuando uno adiciona un nombre de máquina debe adicionarle un signo de dólar (“$”) al nombre la máquina. Esto no debe hacerse con smbpasswd. smbpasswd agrega el signo de dólar por sí solo. Si no se le agrega el signo de dólar al final cuando se usa adduser, ocurrirá un error cuando se adicione el nombre de máquina a samba.
# adduser machine$
|
5.6.2 Network File System (NFS)
NFS (o Network File System - Sistema de Archivos en Red) fue escrito originalmente por Sun para su implementación de Unix, Solaris. Aunque es significativamente más sencillo de poner a correr comparado con SMB, también es significativamente menos seguro. La primera inseguridad en NFS es que es fácil de engañar a la identificación de usuario y grupo de una máquina a otra. NFS es un protocolo sin autenticación. Las versiones futuras del protocolo NFS se están realizando con la seguridad mejorada, pero estas no son comunes en el momento en que se escribe este documento.
La configuración de NFS es gobernada por el archivo /etc/exports. Cuando usted carga el archivo por omisión /etc/exports en un editor, usted verá un archivo vacío con dos líneas comentadas al inicio. Necesitamos adicionar una línea al archivo de exportación para cada directorio que deseemos exportar, con una lista de las estaciones de trabajo cliente que se les permite acceder a este recurso. Por ejemplo, si deseamos exportar el directorio /home/foo para la estación de trabajo Bar, simplemente adicionamos la línea:
/home/foo Bar(rw) |
a nuestro archivo /etc/exports. Debajo, usted encontrará el ejemplo de la página man del archivo exports:
# sample /etc/exports file |
Como usted puede observar, existen varias opciones disponibles, pero la mayoría deben ser muy claras, mirando este ejemplo.
NFS trabaja asumiendo que un usuario dado en esa máquina tiene el mismo identificador de usuario en todas las máquinas de la red. Cuando se realiza un intento de leer o escribir desde un cliente NFS a un servidor NFS, un identificador UID es pasado como parte de la solicitud de escritura/lectura. Este UID es tratado de la misma manera que si la solicitud se realizara desde la máquina local. Como usted puede ver, si uno puede arbitrariamente especificar una UID dada para acceder a determinado recurso en una máquina remota, Cosas Malas (mr) pueden y deben pasar. Como una protección parcial contra esto, cada directorio se monta con la opción root_squash. Esto mapea la UID para cada usuario que diga ser root a una UID diferente, previniendo de esta manera el acceso root a los archivos o carpetas en los archivos exportados. root_squash parece estar habilitado por omisión como medida de seguridad, pero los autores recomiendan especificarlo de todas formas en su archivo /etc/exports.
Usted puede también exportar un directorio directamente desde la línea de comandos en el servidor, utilizando el comando exportfs como sigue:
# exportfs -o rw,no_root_squash Bar:/home/foo
|
Esta línea exporta el directorio /home/foo a la computadora “Bar” y brinda a Bar acceso lectura/escritura. Adicionalmente, el servidor NFS no invocará root_squash, lo que significa que cualquier usuario en Bar con una UID “0” (UID de root) tendrá los mismos privilegios que root en el servidor. La sintaxis luce extraña (usualmente cuando se especifica un directorio en el formato computadora:/directorio/archivo, usted se está refiriendo a un archivo en un directorio en la computadora dada).
Usted encontrará más información en la página man del archivo exports.
Capítulo 6 Configuración de X
6.1 xorgconfig
Este es una interfaz simple mediante menúes, muy parecida al instalador de Slackware. Este simplemente le dice al servidor X que mire a la tarjeta, y configura el archivo inicial de configuración basado en la información que recopila. El archivo /etc/X11/xorg.conf generado debe ser un buen punto de inicio para la mayoría de los sistemas (y debe funcionar sin modificaciones).
Este es un programa de configuración de X basado en texto, que está diseñado para el administrador de sistema avanzado. Aquí hay un pequeño paseo sobre como utilizar xorgconfig. Primero, arranque el programa:
# xorgconfig
|
Esto le va a presentar una pantalla llena de información sobre xorgconfig. Para continuar, presione ENTER. xorgconfig le preguntará para verificar si usted tiene configurado su PATH correctamente. Este debe estar bien así, así que continúe y presione ENTER.




6.2 xorgsetup
La segunda forma de configurar X es utilizar xorgsetup, un programa de configuración automágico que viene con Slackware.
Para correr xorgsetup, inicie sesión como root y teclee:
# xorgsetup
|
Si usted ya tenía un archivo /etc/X11/xorg.conf (porque usted ya había configurado X), se le preguntará si desea respaldar el archivo de configuración existente antes de continuar. El archivo original se renombrará como /etc/X11/xorg.conf.backup.
6.3 xinitrc
xinit(1) es el programa que propiamente arranca X; este es llamado por startx(1); usted puede no haberlo notado, (y probablemente no necesite notarlo realmente). Su archivo de configuración, sin embargo, determina que programa (incluyendo y especialmente el gestor de ventanas) son corridos cuando X levanta. xinit primero chequea su directorio home, buscando un archivo .xinitrc.
Si este archivo existe, es ejecutado; de otra manera se utiliza /var/X11R6/lib/xinit/xinitrc (el del sistema en general).Aquí hay un archivo xinitrc sencillo:
#!/bin/sh |
Todos esos bloques “if” están ahí para fusionar varias configuraciones desde varios archivos. La parte interesante de este archivo está llegando al final, donde son corridos varios programas. Esta sesión X va a comenzar con el gestor de ventanas twm(1), un reloj, y tres terminales. Note el exec antes del último xterm. Lo que hace es reemplazar la consola que está corriendo actualmente (la que está ejecutando este script xinitrc) con este comando xterm(1). Cuando el usuario salga de este xterm, la sesión X terminará.
Para personalizar su inicio de X, copie el archivo por omisión /var/X11R6/lib/xinit/xinitrc hacia ~/.xinitrc y edítelo, reemplazando aquellas líneas de programas por cualesquiera que usted desee. El fin del mío es simplemente:
# Start the window manager: |
Note que existen varios archivos xinitrc.* en /var/X11R6/lib/xinit que corresponden a varios gestores de ventanas e interfaces gráficas. Usted puede utilizar uno de estos, si desea.
6.4 xwmconfig
Durante años, Unix fue usado casi exclusivamente como sistema operativo para servidores, con la excepción de estaciones de trabajo profesionales de alta potencia. Sólo aquellos con inclinaciones técnicas eran probables usuarios de sistemas operativos al estilo Unix, y la interfaz de usuario refleja este hecho. Las interfaces gráficas de usuario (GUIs) tendían a ser justamente huesos desnudos, diseñadas para correr unas pocas aplicaciones gráficas, como programas CAD y renderers de imágenes. La mayoría de los archivos y la gestión del sistema se hacía mediante la línea de comandos. Varios vendedores (Sun Microsystems, Silicon Graphics, etc) vendían estaciones de trabajo con un intento de brindar un estilo coherente, pero la amplia variedad de toolkits para hacer GUIs que utilizaban los desarrolladores llevó inevitablemente a la disolución de la uniformidad en el escritorio. Una barra de desplazamiento puede que no luzca igual en dos aplicaciones diferentes. Los menúes pueden aparecer en diferentes lugares. Los programas pueden tener botones diferentes, y checkboxes. Los colores varían ampliamente, y generalmente estaban codificados en las fuentes de cada toolkit. Pero como los usuarios eran primeramente profesionales técnicos, nada de esto importaba mucho.
Con el advenimiento de los sistemas operativos libres al estilo Unix y el número creciente de aplicaciones gráficas, X ha ganado recientemente una gran cantidad de usuarios de escritorio. La mayoría de los usuarios, por supuesto, están acostumbrados a la visión consistente que brinda Microsoft Windows o MacOS de Apple; la falta de esta consistencia en las aplicaciones basadas en X se han convertido en una barrera para su aceptación más amplia. En respuesta, dos proyectos de código abierto se comenzaron: El K Desktop Environment, o KDE, y el GNU Network Object Model Environment, conocido como GNOME. Cada uno tiene una amplia variedad de aplicaciones, desde barras de tareas y gestores de archivos hasta juegos y suites de oficina, escritas utilizando el mismo toolkit para las GUI y altamente integrados para brindar un escritorio uniforme y consistente.
Las diferencias en KDE y GNOME son generalmente sutiles. Cada uno luce diferente del otro, porque cada uno utiliza un toolkit para sus GUI diferente. KDE está basado en la biblioteca Qt de Troll Tech AS, mientras que GNOME usa GTK, un toolkit originalmente desarrollado para el GNU Image Manipulation Program (o El GIMP, para abreviar). Como proyectos separados, KDE y GNOME tienen cada uno sus propios diseñadores y programadores, con diferentes estilos de desarrollo y filosofías. El resultado en cada caso, sin embargo, ha sido fundamentalmente el mismo: un entorno de escritorio altamente integrado, consistente, y una colección de aplicaciones. La funcionalidad, usabilidad y la belleza pura de ambos KDE y GNOME, son rivales de cualquier otro disponible en otros sistemas operativos.
La mejor parte, además, es que estos escritorios avanzados son libres. Esto significa que usted puede tener uno de ellos, o los dos (sí, al mismo tiempo). La opción es suya.
Además de los escritorios GNOME y KDE, Slackware incluye una larga colección de gestores de ventanas. Algunos han sido diseñados para emular a otros sistemas operativos, algunos para la personalización, otros para la velocidad. Existe mucha variedad. Por supuesto, usted puede instalar cuantos desee, jugar con ellos, y decidir cual le gusta más.
Para hacer la selección del escritorio fácil, Slackware también incluye un programa llamado xwmconfig que puede ser usado para seleccionar un escritorio o gestor de ventanas. Se ejecuta así:
% xwmconfig
|

6.5 xdm
Como Linux se ha convertido en más y más útil como sistema operativo de escritorio, muchos usuarios encuentran deseable que la máquina arranque directamente en un entorno gráfico. Para esto, usted necesitará decirle a Slackware que inicie directamente en las X, y asignar un gestor de inicio gráfico. Slackware viene con tres herramientas de inicio gráfico, xdm(1), kdm, y gdm(1).
xdm es el gestor gráfico de inicio que viene con el sistema X.org. Es ubicuo, pero no tiene tantas características ni alternativas. kdm es el gestor de de inicio que viene con KDE, el K Desktop Environment. Finalmente, gdm es el gestor de inicio que viene con GNOME. Cualquiera de las opciones le va a permitir iniciar sesión con cualquier usuario, y seleccionar que escritorio desea usar.
Desafortunadamente, Slackware no incluye ningún programita lindo como xwmconfig para seleccionar que gestor de inicio de sesión utilizar, así que si los tres están instalados, usted va a tener que hacer un poco de edición para seleccionar el de su preferencia. Pero primero, veamos como iniciar en un entorno gráfico.
Para que X arranque al inicio, usted necesita iniciar en el nivel (runlevel) 4. Los niveles son sencillamente una manera de decirle a init(8) que haga algo diferente cuando inicia el sistema operativo. Hacemos esto editando el archivo de configuración para init, /etc/inittab.
# These are the default runlevels in Slackware: |
Para que Slackware inicie en un entorno gráfico, solamente cambiamos 3 por 4.
# Default runlevel. (Do not set to 0 or 6) |
Ahora Slackware iniciará en el nivel 4, y ejecutará /etc/rc.d/rc.4. Este archivo inicia X y llama al gestor de inicio de sesión que usted ha seleccionado. Entonces, ¿Cómo seleccionamos el gestor de inicio de sesión? Hay pocas maneras de hacer esto, y las explicaré después de mirar rc.4.
# Try to use GNOME's gdm session manager: |
Como usted puede ver aquí, rc.4 primero chequea para ver si gdm es ejecutable, y si lo es lo corre. Segundo en la lista está kdm, y finalmente xdm. Una manera de seleccionar un gestor de inicio de sesión es simplemente eliminar los que usted no desee utilizando removepkg. Usted puede encontrar más información sobre removepkg en el Capítulo 18.
Opcionalmente, usted puede eliminar los permisos de ejecución para aquellos archivos que usted no desea utilizar. Discutimos chmod en el Capítulo 9.
# chmod -x /usr/bin/gdm
|
Finalmente, usted puede sencillamente comentar las líneas para el gestor de inicio que usted no desea utilizar.
# Try to use GNOME's gdm session manager: |
Cualquier línea precedida por el signo de número(#) es considerado comentario y el intérprete de comandos los ignora silenciosamente. Por ende, aunque gdm esté instalado y sea ejecutable, el intérprete de comandos (en este caso bash) no se molestará en preguntar por él.
Capítulo 7 Iniciando
7.1 LILO
El Linux Loader, o LILO, es el cargador más popular en uso en los sistemas Linux. Es muy configurable y puede ser usado fácilmente para iniciar otros sistemas operativos.
Slackware Linux viene con una utilidad de configuración basada en menúes, llamada liloconfig. Este programa es corrido primero durante el proceso de configuración, pero usted puede invocarlo más tarde tecleando liloconfig en la consola.
LILO lee sus configuraciones desde el archivo /etc/lilo.conf(5). Estas no se leen cada vez que usted inicia, sino que se leen cada vez que usted instala LILO. LILO debe ser reinstalado en el sector de arranque cada vez que usted haga un cambio de configuración. Muchos errores con LILO suceden debido a que usted hace un cambio en el archivo lilo.conf, pero no corre de nuevo lilo para instalar estos cambios. liloconfig le ayudará a construir el archivo de configuración para que usted pueda instalar LILO en su sistema. Si usted prefiere editar /etc/lilo.conf a mano, reinstalar LILO solo significa teclear /sbin/lilo (como root) en la consola.
Cuando usted invoca por primera vez a liloconfig, este debe verse así:


7.2 LOADLIN
La otra opción de inicio que viene con Slackware Linux es LOADLIN. LOADLIN es un ejecutable de DOS que puede ser utilizado para iniciar Linux desde un sistema DOS que esté corriendo. Este requiere que el núcleo de Linux esté en una partición DOS de manera que LOADLIN pueda cargarlo e iniciar el sistema adecuadamente.
Durante el proceso de instalación, LOADLIN es copiado en el directorio home de root como un archivo .ZIP. No existe un proceso automatizado de instalación para LOADLIN. Usted necesitará copiar el núcleo de Linux (típicamente /boot/vmlinuz) y el archivo LOADLIN desde el directorio home de root hacia la partición DOS.
LOADLIN es útil si usted desea hacer un menú de inicio en su partición DOS. Un menú puede ser adicionado en su archivo AUTOEXEC.BAT que le puede permitir seleccionar entre DOS y Linux. La opción Linux debe correr LOADLIN, iniciando por ende su sistema Slackware. Este archivo AUTOEXEC.BAT bajo Windows 95 debe brindar un menú de inicio suficiente:
@ECHO OFF |
Usted debe especificar su partición raíz con su nombre de dispositivo bajo Linux, como /dev/hda2 o algo por el estilo. Usted siempre puede utilizar LOADLIN en la línea de comandos. Usted simplemente lo puede usar de la misma manera que en el ejemplo de arriba. La documentación de LOADLIN viene con muchos ejemplos de como usarlo.
7.3 Inicio Dual
Muchos usuarios configuran sus computadoras para iniciar Slackware Linux y otro sistema operativo. Hemos descrito a continuación escenarios típicos de inicios duales, en caso de que usted esté teniendo dificultades a la hora de configurar su sistema.
7.3.1 Windows
Configurar una computadora con MS Windows y Linux es probablemente el escenario de inicio dual más común. Existen numerosas formas de configurar el inicio, pero en esta sección se cubrirán dos.
Frecuentemente, cuando se configura un sistema con inicio dual, la persona hace un plan perfecto de donde irá cada cosa, pero se pierde en el orden de instalación. Es muy importante entender que los sistemas operativos necesitan ser instalados en cierto orden para que el inicio dual funcione. Linux siempre brinda control sobre lo que se escribe en el Master Boot Record. Por ende, siempre es recomendable instalar Linux de último. Windows debe ser instalado primero, ya que siempre va a escribir su cargador de inicio en el MBR, sobreescribiendo cualquier entrada que Linux hubiese puesto ahí.
7.3.1.1 Utilizando LILO
La mayoría de las personas quieren utilizar LILO para seleccionar entre Linux y Windows. Como se mencionó antes, usted debe instalar Windows primero, luego Linux.
Digamos que usted tiene un disco duro IDE de 40 GB que es la única unidad en su sistema. Digamos también que usted desea dar la mitad del espacio a Windows, y la mitad a Linux, así:
20GB Windows boot (C:) |
Usted debe además poner una partición de tamaño adecuado para el intercambio de Linux (swap). La regla no escrita es usar el doble de la cantidad de RAM que tengas en espacio en disco duro. Un sistema de 64MB debe tener 128MB de swap, y así. El espacio adecuado de intercambio provoca grandes discusiones en IRC y Usenet. Realmente, no hay una manera “correcta” de hacerlo, pero apegarse a la regla anterior debe ser suficiente.
Con sus particiones hechas, usted debe proceder a instalar Windows. Después de que esté configurado y corriendo, usted debe instalar Linux. La instalación de LILO necesita especial atención. Usted debe seleccionar el modo experto para instalar LILO.
Comience una nueva configuración de LILO. Usted debe instalarlo en el Master Boot Record, para que pueda ser utilizado por los dos sistemas operativos. Desde el menú, adicione su partición de Linux y su partición Windows (o DOS). Una vez que esto esté completo, puede instalar LILO.
Reinicie la computadora. LILO debe cargar y mostrar un menú, permitiendo seleccionar entre los dos sistemas operativos que tiene instalado. Seleccione el nombre del sistema operativo que desee cargar (estos nombres fueron seleccionados cuando usted configuró LILO).
LILO es un cargador de inicio muy configurable. No solo se limita a iniciar Linux o DOS. Él puede cargar casi cualquier cosa. Las páginas man para lilo(8) y lilo.conf(5) brindan información más detallada.
¿Qué pasa si LILO no funciona? Existen instancias donde LILO sencillamente no funciona en una máquina en particular. Afortunadamente, existe otra manera de iniciar dual Windows y Linux.
7.3.1.2 Utilizando LOADLIN
Este método puede ser utilizado si LILO no funciona en su sistema, o simplemente si usted no desea configurar LILO. Este método es también ideal para el usuario que reinstala Windows con frecuencia. Cada vez que usted reinstala Windows, este sobreescribe el Master Boot Record, destruyendo cualquier instalación de LILO. Con LOADLIN, usted no está sujeto a ese problema. La mayor desventaja es que usted solo puede usar LOADLIN para cargar Linux.
Con LOADLIN, usted puede instalar los sistemas operativos en cualquier orden que desee. Sea cuidadoso a la hora de instalar cosas en su Master Boot Record, usted puede que no desee hacer eso. LOADLIN descansa en que la partición de Windows sea arrancable (bootable), así que durante la instalación de Slackware, asegúrese de saltar la configuración de LILO.
Después de instalar los sistemas operativos, copie el archivo loadlinX.zip (donde X es el número de versión, digamos, 16a) desde el directorio home de root hacia su partición Windows. También copie la imagen de su núcleo hacia la partición Windows. Usted necesitará estar en Linux para que esto funcione. Este ejemplo muestra como hacerlo:
# mkdir /win |
Esto debe crear un directorio C:\LINUX en su partición Windows (asumiendo que es /dev/hda1) y copiar todo lo necesario para LOADLIN. Después de hacer esto, usted necesitará reiniciar e ir a Windows para configurar un menú de arranque.
Una vez en Windows, vaya a la línea de comandos de DOS. Primero, debemos asegurarnos de que el sistema no inicie con la interfaz gráfica.
C:\> cd \ |
Adicione esta línea al archivo:
BootGUI=0 |
Ahora salve el archivo y salga del editor. Ahora edite C:\AUTOEXEC.BAT para que podamos adicionar el menú de arranque. Lo siguiente brinda un ejemplo de como debe lucir un bloque de arranque en AUTOEXEC.BAT:
cls |
La línea clave es la que corre LOADLIN. Le decimos que núcleo cargar, la partición raíz de Linux, y que la queremos solo lectura al principio.
Las herramientas para estos dos métodos son brindadas por Slackware Linux. Existen numerosos otros cargadores de arranque en el mercado, pero estos deben funcionar para la mayoría de las configuraciones de inicio dual.
7.3.1.3 Hack desechado de Windows NT
Esta es la situación menos común de inicio dual. Hace tiempo, LILO no era capaz de iniciar Windows NT, requiriendo que los usuarios de Linux modificaran NTLDR, lo cual presentaba mayores problemas que el inicio dual entre Windows 9x y Linux. Entienda que las instrucciones siguientes están desechadas. LILO es capaz de arrancar Windows NT/2000/XP/2003 desde hace muchos años. Si usted está utilizando una máquina antigua, usted puede que necesite esta clase de modificaciones.
-
Instale Windows NT
-
Instale Linux, asegurándose de que LILO es instalado en el superbloque de la partición Linux
-
Obtenga los primeros 512 bytes de la partición raíz de Linux y almacénelos en la partición de Windows NT.
-
Edite C:\BOOT.INI bajo Windows NT para adicionar la opción Linux
Instalar Windows NT debe ser bastante sencillo, como instalar Linux. A partir de ahí, se pone algo truculento. Grabar los primeros 512 bytes de la partición de Linux es más sencillo de los que parece. Usted necesitará estar en Linux para realizar esto. Asumiendo que su partición de Linux es /dev/hda2, ejecute este comando:
# dd if=/dev/hda2 of=/tmp/bootsect.lnx bs=1 count=512
|
Eso es todo. Ahora usted necesita copiar bootsect.lnx hacia la partición Windows NT. Es aquí donde caemos en otro problema. Linux no tiene soporte de escritura estable para el sistema de archivos NTFS. Si usted instaló Windows NT y formateó su unidad como NTFS, usted necesitará copiar este archivo hacia un disquete FAT y entonces leerlo bajo Windows NT. Si usted formateó la unidad Windows NT como FAT, usted puede simplemente montarla bajo Linux y copiar el archivo. De cualquier manera, usted debe pasar /tmp/bootsect.lnx desde la unidad Linux hacia C:\BOOTSECT.LNX en la unidad Windows NT.
El último paso es adicionar una opción al menú de inicio de Windows NT. Bajo Windows NT abra una línea de comandos
C:\WINNT> cd \ |
Adicione esta línea al final del archivo:
C:\bootsect.lnx="Slackware Linux" |
Salve los cambios y salga del editor. Cuando usted reinicie Windows NT, usted tendrá la opción Linux en el menú. Seleccionándola arrancará en Linux.
7.3.2 Linux
Si , la gente de verdad lo hace. Este es definitivamente el escenario más fácil de inicio dual. Usted simplemente utilice LILO y agregue más entradas al archivo /etc/lilo.conf. Eso es todo hasta aquí.
Capítulo 8 La Consola
8.1 Usuarios
8.1.1 Iniciando Sesión
Así que usted ha arrancado el sistema, y está mirando a algo que se parece a esto:
Welcome to Linux 2.4.18 |
Hmm.. nadie dijo nada acerca de un inicio de sesión. ¿Y qué es darkstar? No se preocupe; lo más seguro es que usted no haya disparado un enlace de comunicaciones del hiperespacio con la luna artificial del Imperio. (Me temo que el protocolo de enlace de comunicaciones del hiperespacio no está soportado actualmente en el núcleo de Linux. Tal vez la rama 2.8 del núcleo al fin brinde este soporte tan necesario.) No, darkstar es solo el nombre de una de nuestras computadoras, y su nombre queda puesto por omisión. Si usted especificó un nombre para su computadora durante la instalación, usted debe verlo en lugar de darkstar.
Y para el inicio de sesión... Si esta es su primera vez, usted debe iniciar sesión como root. Se le preguntará una contraseña; si usted puso una durante la instalación, es la que estamos buscando. Si no, sencillamente oprima enter. Eso es todo-- ¡Ya está dentro!
8.1.2 Root: El Superusuario
Ok, ¿quién o qué es root? ¿Y qué está haciendo con una cuenta en su sistema?
Bien, en el mundo de Unix y sistemas operativos similares (como Linux), existen usuarios y luego usuarios. Tendremos más detalles después, pero lo importante que se debe conocer es que root es el usuario por encima de todos los usuarios; root es plenipotente y todo lo sabe, y nadie desobedece a root. Sencillamente no está permitido. root es lo que llamamos un “superusuario”, y es eso exactamente. Y lo mejor de todo, root es usted.
¿Grandioso, heh?
Si usted no está seguro: si, es de veras grandioso. La cosa es que a root le está permitido romper todo si así lo desea. Usted debe ir a la Sección 12.1.1 y ver como se adiciona un usuario; entonces iniciar sesión como ese usuario y trabajar desde ahí. La sabiduría tradicional dice que es mejor solo hacerse superusuario cuando sea absolutamente necesario, para minimizar las posibilidades de romper algo por accidente.
A propósito, si usted decide que desea ser root mientras está iniciada su sesión como alguien más, no hay problema. Sencillamente use el comando su(1). Se le preguntará la contraseña de root y entonces usted será root hasta que salga con exit o con logout. Usted puede convertirse en otro usuario utilizando su, dado que usted conozca la contraseña de este: su logan, por ejemplo, lo hará ser yo.
|
root puede hacer su a cualquier usuario, sin necesitar su contraseña. |
8.2 La Línea de Comandos
8.2.1 Corriendo Programas
Es difícil quedar satisfecho sin correr un programa; usted puede apuntalar algo con su computadora, o mantener con ella abierta una puerta, e incluso hará un ruidito muy cariñoso mientras funciona, pero nada más. Y creo que todos podemos estar de acuerdo en que este uso como calzo de puerta ruidoso no fue lo que le dió la popularidad que goza la computadora personal.
¿Recuerda que casi todo en Linux es un archivo? Bien, eso se aplica a los programas también. Cada comando que corra (que no se encuentre en la consola) reside en un archivo, en alguna parte. Usted corre un programa simplemente especificando el camino completo hasta él.
Por ejemplo, ¿recuerda aquel comando su de la última sección? Realmente se encuentra en el directorio /bin: /bin/su debe correrlo gustosamente.
¿Entonces por qué simplemente tecleando su funciona? Después de todo, usted no dijo que estuviera en /bin. Fácilmente podría haber estado en /usr/local/share, no? ¿Cómo lo supo? La respuesta a eso reside en la variable de entorno PATH (camino); la mayoría de las consolas tienen PATH o algo muy similar a PATH. Este básicamente contiene una lista de directorios en los cuales buscar los programas que usted intenta correr. Así que cuando usted corra su, la consola buscará en su lista de directorios, chequeando en cada uno la existencia de un archivo ejecutable llamado su para correrlo; el primero al que llegue, lo corre. Esto sucede siempre que usted corra un programa sin especificar el camino completo hasta él; si usted obtiene un mensaje de error al estilo ““Command not found””, esto sencillamente significa que el programa que usted intentó correr no está en su PATH. (por supuesto, esto debe ser cierto si el programa no existe del todo...) Discutiremos las variables de entorno con más detalles en la Sección 8.3.1.
También recuerde que “.” es una abreviatura para el directorio actual, así que si sucede que usted está en /bin, ./su debe funcionar como si fuera explícitamente el camino completo.
8.2.2 Utilizando Comodines
Casi todas las consolas reconocen algunos caracteres como sustitutos o abreviaturas que significan que cualquier cosa va ahí. Esos caracteres se llaman apropiadamente comodines; los más comunes son * y ?. Por convenio, ? usualmente significa un solo caracter cualquiera. Por ejemplo, suponga que usted está en un directorio con tres archivos: ex1.txt, ex2.txt, y ex3.txt. Usted desea copiar todo esos archivos (usando el comando cp que cubrimos en la Sección 10.5.1) hacia otro directorio, digamos /tmp. Bien, teclear cp ex1.txt ex2.txt ex3.txt /tmp es definitivamente mucho trabajo. Es mucho más fácil teclear cp ex?.txt /tmp; el ? va a hacer la función de los caracteres “1”, “2”, y “3”, y a sustituirlos.
¿Qué ha dicho usted? ¿Que aún es mucho trabajo? Está en lo cierto. Es espantoso; tenemos leyes de trabajo que nos protegen de esa clase de cosas. Afortunadamente, también tenemos el *. Como ya dijimos, * corresponde con “cualquier número de caracteres”, incluyendo 0. Así que si esos tres archivos estuviesen solos en el directorio, podríamos decir simplemente cp * /tmp y tenerlos todos allá de un solo barrido. Suponga, además, que también hay un archivo llamado ex.txt y uno llamado hejaz.txt. Queremos copiar ex.txt pero no hejaz.txt; cp ex* /tmp hará eso por nosotros.
cp ex?.txt /tmp, debería, por supuesto, obtener solo nuestros tres archivos originales; no existe ningún caracter en ex.txt que corresponda con el ?, así que quedaría fuera.
Otro comodín común es el par de corchetes [ ]. Cualquier caracter dentro de los corchetes será sustituido en lugar de [ ] para hallar concordancias. ¿Suena confuso? No es tan malo. Suponga, por ejemplo, que tenemos un directorio que contiene los siguientes 8 archivos: a1, a2, a3, a4, aA, aB, aC, y aD . Queremos solo hallar los archivos que terminen en números; [ ] hará esto por nosotros.
% ls a[1-4] |
Pero si queremos solamente a1, a2, y a4? En el ejemplo anterior utilizamos - para significar todos los valores entre 1 y 4. También podemos separar entradas individuales por comas.
% ls a[1,2,4] |
Sé lo que está pensando ahora “¿Bien, y qué se hace con las letras?” Linux es sensible a las mayúsculas, lo que significa que a y A son caracteres diferentes y solo tienen relación en su mente. Las mayúsculas siempre vienen antes de las minúsculas, así que A y B vienen antes de a y b. Continuando con nuestro ejemplo anterior, si deseamos los archivos a1, y A1, podemos encontrarlos rápidamente con [ ].
% ls [A,a]1 |
Note, que si hubiésemos puesto un guión en lugar de la coma, hubiésemos obtenido resultados incorrectos.
% ls [A-a]1 |
Usted puede también combinar cadenas con guión y comas.
% ls [A,a-d] |
8.2.3 Redireccionamiento de Entrada/Salida y Conductos
(Aquí viene algo bien bueno.)
% ps > blargh
|
¿Usted sabe lo que es esto? Ese soy yo corriendo ps para ver que procesos están corriendo; ps es cubierto en la Sección 11.3. Esa no es la parte buena. La parte buena es > blargh, la cual significa, crudamente, toma la salida de ps y escríbela en un archivo llamado blargh. Pero espere, esto se pone mejor.
% ps | less
|
Este toma la salida de ps y la conduce hacia less, para que yo pueda desplazarme a través de ella a mi antojo.
% ps >> blargh
|
Este el es tercer redirector más comúnmente usado; este hace lo mismo que “>”, excepto que “>>” va a agregar la salida de ps al archivo blargh, si dicho archivo existe. Si no, como mismo hace “>”, este será creado. (“>” va a destruir el contenido actual de blargh.)
Existe también el operador “<”, el cual significa tomar su entrada desde lo siguiente, pero no se utiliza con tanta frecuencia.
% fromdos < dosfile.txt > unixfile.txt
|
La redirección se pone realmente divertida cuando usted comienza a apilarla:
% ps | tac >> blargh
|
Esto va a correr ps, invertir las líneas de su salida, y adicionarla al archivo blargh. Usted puede apilar tantas de esas como desee; solo tenga cuidado de recordar que son interpretadas de izquierda a derecha.
Vea la página man de bash(1) para obtener información más detallada sobre redireccionamiento.
8.3 El Bourne Again Shell (bash)
8.3.1 Variables de Entorno
Un sistema Linux es una bestia compleja, y hay mucho de qué ocuparse, muchos pequeños detalles que vienen a jugar en su interacción normal con varios programas (algunos de los cuales usted ni siquiera está enterado de que existen). Nadie desea pasar un montón de opciones a cada programa que corre, diciéndole que terminal está siendo usado, el nombre de la computadora, o cómo debe lucir el prompt.
Así que como mecanismo de copia, los usuarios tienen lo que se denomina entorno. El entorno define las condiciones en las cuales el programa corre, y como algunas de esas definiciones son variables, el usuario puede alterarlas y jugar con ellas, lo cual es correcto solo en sistemas Linux. Casi seguro que cualquier consola tendrá sus variables de entorno (si no, probablemente no sea una consola muy usable). Aquí daremos una panorámica de los comandos que bash brinda para manipular sus variables de entorno.
set por sí solo le mostrará todas las variables de entorno que están actualmente definidas, así como sus valores. Como la mayoría de los comandos internos de bash, este también puede hacer otras cosas (con parámetros); aunque le dejaremos a la página man de bash(1) la cobertura de ese tema. El Ejemplo 8-1 muestra una salida de un comando set que corrió en una de las computadoras del autor. Note en este ejemplo la variable PATH, discutida anteriormente. Los programas en cualquiera de esos directorios pueden ser corridos simplemente tecleando su nombre de archivo base.
Ejemplo 8-1. Listando Variables de Entorno con set
% set |
% unset VARIABLE
|
% export VARIABLE=algún_valor
|
% export PATH=$PATH:/algún/nuevo/directorio
|
% echo $PATH |
8.3.2 Completamiento con Tab
(Aquí viene algo bueno de nuevo.)
-
Una interfaz de línea de comandos significa teclear mucho.
-
Teclear es trabajo.
-
A nadie le gusta el trabajo.
De 3 y 2, podemos determinar que (4) a nadie le gusta teclear. Afortunadamente, bash nos salva de (5) (a nadie le gusta una interfaz de línea de comandos).
¿ Como bash logra esta magnífica característica?, se preguntará. Además de la expansión con comodines, bash incluye el completamiento con tab.
El completamiento con Tab funciona más o menos así: Usted está tecleando el nombre de un archivo. Tal vez está en su PATH, tal vez usted lo está tecleando explícitamente. Todo lo que usted tiene que hacer es teclear el nombre del fichero solamente hasta que quede identificado únicamente. Entonces, apriete la tecla Tab. bash debe imaginarse lo que usted desea y ¡terminará de teclearlo para usted!
Hora de ejemplos: /usr/src contiene dos subdirectorios: /usr/src/linux y /usr/src/sendmail. Yo quiero ver que hay en /usr/src/linux. Entonces, sencillamente tecleo ls /usr/src/l, oprimo la tecla TAB, y bash me da ls /usr/src/linux.
Ahora, suponga que existen dos subdirectorios /usr/src/linux y /usr/src/linux-old; Si yo tecleo /usr/src/l y oprimo TAB, bash llenará tanto como pueda, y yo obtendré /usr/src/linux. Puedo parar ahí, o puedo apretar TAB de nuevo, y bash mostrará una lista de directorios que estén de acuerdo con lo que yo haya tecleado hasta ese momento.
Por ende, menos tecleo (y por ende, a las personas puede agradarle la línea de comandos). Le dije al comienzo que esto estaba bueno.
8.4 Terminales Virtuales
Digamos que usted está en medio de cualquier tarea y decide hacer algo más. Usted puede simplemente desechar lo que está haciendo, e intercambiar de tarea, pero esto es un sistema multiusuario ¿no es cierto?. Y usted puede iniciar tantas sesiones simultáneas como desee ¿no es cierto? Entonces, ¿por qué razón hacer una sola cosa al mismo tiempo?
Usted no tiene por qué. Nosotros no podemos tener múltiples teclados, ratones, y monitores para una máquina; ya que la mayoría de nosotros no lo necesita. Evidentemente, el hardware no es la solución. Solo queda entonces el software, y Linux se encarga de esto, brindando "terminales virtuales" o "VTs".
Presionando Alt y una tecla de funciones, usted puede intercambiar entre terminales virtuales; a cada tecla de función le corresponde uno. Slackware tiene inicio de sesiones en 6 VTs por omisión. Alt+F2 lo llevará al segundo, Alt+F3 al tercero, etc.
El resto de las teclas de funciones están reservadas para sesiones X. Cada sesión X usa su propio VT, comenzando por el séptimo (Alt+F7) en adelante. Cuando esté en X, la combinación Alt+Tecla de función es reemplazada por Ctrl+Alt+Función; así que si usted está en X y desea regresar a un inicio de sesión texto (sin salir de su sesión X) Ctrl+Alt+F3 lo llevará al tercero. (Alt+F7 lo traerá de regreso, asumiendo que usted utilice la primera sesión X.)
8.4.1 Pantalla
Pero ¿qué sucede en aquellos casos en los cuales no existen los terminales virtuales?¿Qué hacer en ese caso? Afortunadamente, Slackware incluye un bonito gestor de pantallas llamado screen. screen es un emulador de terminal que tiene posibilidades similares a las de un terminal. Al ejecutar screen parpadea una breve introducción, y luego cae a un terminal. A diferencia de los terminales virtuales estándar, screen tiene sus propios comandos. Todos los comandos de screen comienzan con la combinación Ctrl+A. Por ejemplo, Ctrl+A+C creará una nueva sesión de terminal. Ctrl+A+N seleccionará el próximo terminal. Ctrl+A+P selecciona el terminal anterior.
screen también soporta adjuntar o prescindir de sesiones de screen, lo cual es particularmente útil para sesiones remotas vía ssh y telnet, (hablaremos de ellos más tarde). Ctrl+A+D prescindirá de la pantalla que está corriendo actualmente. Ejecutando screen -r se muestran las sesiones actuales que está corriendo, a las cuales usted puede adjuntarse.
% screen -r |
Corriendo screen -r 1212 le adjuntará la primera pantalla de la lista. Ya mencioné anteriormente cuan útil era esto para las sesiones remotas. Si yo estuviera iniciado en un Slackware remoto vía ssh, y mi conexión estuviera dañada severamente por algún evento casual, como un fallo local de la electricidad, cualquier cosa que estuviera haciendo en ese momento perecería instantáneamente, lo cual podría ser horrible para su servidor. Usar screen previene esto prescindiendo de mi sesión si la conexión está caída. Una vez que mi conexión se restaure, puedo readjuntar mi sesión y terminar lo que estuviera haciendo en el mismo punto en el que lo dejé.
Capítulo 9 Estructura del Sistema de Archivos
9.1 Propiedad
El sistema de archivos almacena la información de propiedad para cada archivo y directorio en el sistema. Esto incluye qué usuario y grupo posee un archivo en particular. La manera más sencilla de ver esta información es con el comando ls:
% ls -l /usr/bin/wc |
Estamos interesados en la tercera y cuarta columna. Estas contienen el nombre de usuario y grupo del propietario de este archivo. Podemos ver que el usuario “root” y el grupo “bin” son los propietarios de este archivo.
Podemos cambiar fácilmente los propietarios de determinado archivo con los comandos chown(1) (que significa “change owner”, cambiar propietario) y chgrp(1) (que significa “change group”, cambiar grupo). Para cambiar el dueño a daemon, podemos utilizar chown:
# chown daemon /usr/bin/wc
|
Para cambiar el grupo propietario a “root”, podemos usar chgrp:
# chgrp root /usr/bin/wc
|
Podemos también usar chown para especificar el usuario y grupo que posee determinado archivo:
# chown daemon:root /usr/bin/wc
|
En el ejemplo anterior, el usuario podría haber usado un punto en vez de los dos puntos,. El resultado sería el mismo; de todas maneras, los dos puntos se consideran una mejor forma. El uso del punto está desechado, y puede ser eliminado de versiones futuras de chown para permitir nombres de usuario que incluyan puntos. Estos nombres de usuario tienden a ser muy populares en los servidores Windows Exchange, y son muy comunes en direcciones de correo electrónico, por ejemplo: mr.jones@example.com. En Slackware, los administradores están prevenidos a mantenerse alejados de estos nombres de usuarios, ya que algunos scripts aún utilizan el punto para indicar el usuario y grupo de un archivo o directorio. En nuestro ejemplo, chmod debe interpretar mr.jones como usuario “mr” y grupo “jones”.
La propiedad de archivos es una parte muy importante en el uso de un sistema Linux, incluso si usted es el único usuario. A veces necesitará ajustar la propiedad de algunos archivos, o nodos de dispositivos.
9.2 Permisos
Los permisos son otra parte importante de los aspectos multiusuario del sistema de archivos. Con estos usted puede cambiar quien puede leer, escribir, y ejecutar archivos.
La información de permisos se almacena como cuatro dígitos octales, cada uno especifica un grupo diferente de permisos. Existen permisos para el propietario, para el grupo, y para el resto del mundo. Los cuatro dígitos octales se utilizan para almacenar información especial sobre la identificación de usuario, la identificación del grupo, y el bit "sticky". Los valores octales asignados a los modos de permisos son los siguientes (estos también tienen letras asociadas con ellos, las cuales son mostradas por programas como ls y pueden ser usadas por chmod):
Tabla 9-1. Valores de Permisos Octales
| Tipo de Permiso | Valor Octal | Valor Letra |
|---|---|---|
| bit “sticky” | 1 | t |
| Poner identificador de usuario | 4 | s |
| Poner identificador de grupo | 2 | s |
| leer | 4 | r |
| escribir | 2 | w |
| ejecutar | 1 | x |
Los permisos por omisión de bash son:
% ls -l /bin/bash |
% touch /tmp/example |
% chmod 755 /tmp/example |
Ahora usted puede estar pensando, "¿ Por qué no se creó el archivo con esos permisos desde el principio?" La respuesta es sencilla. bash incluye una pequeña estructura llamada umask. Esta está incluida en la mayoría de las líneas de comando de Unix, y controla los permisos que se asignan a los archivos que se creen nuevos. Discutimos las estructuras internas de bash hasta determinado grado en la Sección 8.3.1. umask nos toma un poco para acostumbrarnos. Funciona de manera similar a chmod, solo que al revés. Usted especifica los valores octales que usted no desea que existan en los archivos que se creen nuevos. El valor por omisión de umask es 0022.
% umask |
Vea la página man de bash para obtener más información.
Para poner permisos especiales con chmod, adicione los números juntos y póngalos en la primera columna. Por ejemplo, para hacer que ponga el identificador de usuario y grupo, usamos 6 en la primera columna:
% chmod 6755 /tmp/example |
Si los valores octales lo confunden, usted puede utilizar letras con chmod. Los grupos de permisos se representan como:
Para hacer lo anterior, podíamos haber usado varias líneas de comandos:
% chmod a+rx /tmp/example |
% ls -l /tmp/ |
9.3 Enlaces
Los enlaces son punteros entre archivos . Con los enlaces, usted puede tener archivos que existan en diferentes lugares y que sean accesibles bajo diversos nombres. Existen dos tipos de enlaces: fuertes y débiles.
Los enlaces fuertes son nombres para un archivo en particular. Estos solo pueden existir en un solo sistema de archivos, y solo se eliminan cuando el nombre real es eliminado del sistema. Estos son útiles en algunos casos, pero muchos usuarios encuentran que el enlace débil es más versátil.
El enlace débil, también conocido como enlace simbólico (symlink), puede apuntar a un archivo fuera del sistema de archivos. Realmente es un pequeño archivo que contiene la información que necesita. Usted puede adicionar o eliminar enlaces débiles sin afectar el archivo actual. Y como los enlaces simbólicos son realmente un pequeño archivo que contiene su propia información, incluso puede apuntar a un directorio. Es muy común tener /var/tmp como un enlace simbólico a /tmp por ejemplo.
Los enlaces no tienen su propio grupo de permisos ni propietarios, sino que reflejan aquellos del archivo a los cuales apuntan. Slackware utiliza mayormente enlaces débiles. Este es un ejemplo común:
% ls -l /bin/sh |
La consola sh en Slackware es realmente bash. Para eliminar los enlaces se utiliza rm. El comando ln se utiliza para crear los enlaces. Estos comandos serán discutidos con profundidad en el Capítulo 10.
Es muy importante tener cuidado con los symlinks. Una vez, yo estaba trabajando en una máquina que fallaba consistentemente a la hora de realizar las copias de respaldo en cintas todas las noches. Dos enlaces simbólicos se habían creado en dos directorios, uno apuntando al otro. El programa de respaldo se mantenía copiando los mismos dos directorios hacia la cinta hasta que se quedaba sin espacio. Normalmente, un grupo de medidas de chequeo debe evitar casos como este, pero este fue un caso muy especial.
9.4 Montando Dispositivos
Como se discutió previamente en la Sección 4.1.1, todas las unidades y los dispositivos de su computadora son un gran sistema de archivos. Varias particiones de disco duro, CD-ROMs, y disquetes son dispuestos en el mismo árbol. Para poder adjuntar estas unidades al sistema de archivos de manera que usted pueda acceder a ellas, deben utilizarse los comandos mount(1) y umount(1).
Algunos dispositivos se montan automáticamente cuando usted inicia su computadora. Estos se listan en el archivo /etc/fstab. Cualquier cosa que usted desee que se monte automáticamente tiene una entrada en ese archivo. Para otros dispositivos, usted tendrá que ejecutar un comando cada vez que usted desee utilizar ese dispositivo.
9.4.1 fstab
Veamos un ejemplo de un archivo /etc/fstab:
% cat /etc/fstab |
La primera columna es el nombre de dispositivo. En este caso, los dispositivos están esparcidos en cinco particiones, en dos discos duros SCSI, dos sistemas de archivos especiales que no necesitan dispositivos, un disquete, y una unidad de CD-ROM. La segunda columna dice donde el dispositivo debe ser montado. Esto necesariamente debe ser el nombre de un directorio, excepto en el caso de una partición de intercambio (swap). La tercera columna es el tipo de sistema de archivo del dispositivo. Para sistemas de archivos normales en Linux, esto debe ser ext2 (second extended filesystem, segundo sistema de archivos extendido). Las unidades de CD-ROM tienen iso9660, y los dispositivos basados en Windows pueden tener msdos o vfat.
La cuarta columna es un listado de las opciones que se le aplican al sistema de archivos montado. Lo que viene por omisión normalmente está bien para casi todo. De cualquier modo, a los dispositivos de solo lectura se le debe brindar la bandera ro. Existen muchas opciones que pueden ser utilizadas. Revise la página man de fstab(5) para obtener más información. Las últimas dos columnas son utilizadas por fsck y otros comandos que necesitan manipular los dispositivos. Revise la página man para obtener también esta información.
Cuando usted instala Slackware Linux, el programa de instalación va a construir gran parte del archivo fstab.
9.4.2 mount y umount
Adjuntar otro dispositivo a su sistema de archivos es fácil. Todo lo que tiene que hacer es utilizar el comando mount, con unas pocas opciones. El uso de mount puede simplificarse mucho si el dispositivo tiene una entrada en el archivo /etc/fstab. Por ejemplo, digamos que yo quiero montar mi unidad de CD-ROM y que mi archivo fstab es igual que el mostrado en la sección anterior. Yo llamaría a mount así:
% mount /cdrom
|
Como en fstab hay una entrada para el punto de montaje, mount sabe que opciones utilizar. Si no hubiese una entrada para ese dispositivo, yo tendría que usar muchas opciones para mount:
% mount -t iso9660 -o ro /dev/cdrom /cdrom
|
Esta línea de comandos incluye la misma información que fstab en el ejemplo, pero iremos por partes, de cualquier manera. El -t iso9660 es el sistema de archivos que más comúnmente se utiliza en unidades de CD-ROM. El -o ro le dice a mount que monte el dispositivo como solo lectura. El nombre del dispositivo a montar es /dev/cdrom y /cdrom es la localización en el sistema de archivos para montar la unidad.
Antes de que usted pueda sacar un disquete, CD-ROM, u otro dispositivo removible que esté actualmente montado, usted tendrá que desmontarlo. Esto se realiza mediante el comando umount. No me pregunte donde fué la “n” porque no podría decirle. Usted puede utilizar tanto el nombre de dispositivo como el punto de montaje como argumento para umount. Por ejemplo, si usted desea desmontar el CD-ROM del ejemplo anterior, cualquiera de estos dos comandos funcionará:
# umount /dev/cdrom |
9.5 Montando NFS
NFS significa Network Filesystem (Sistema de archivos de Red). Realmente no es parte del sistema de archivos, pero puede utilizarse para agregar partes al sistema de archivo montado.
Los grandes entornos Unix a veces comparten los mismos programas, grupos de directorios home, y el spool de correo. El problema de tener la misma copia en cada máquina se resuelve con NFS. Podemos utilizar NFS para compartir un grupo de directorios home entre todas las estaciones de trabajo. La estación de trabajo monta este recurso compartido con NFS como si estuviera en la propia máquina.
Vea la Sección 5.6.2 y las páginas man para exports(5), nfsd(8), y mountd(8) para obtener más información.
Capítulo 10 Gestionando Archivos y Directorios
10.1 Navegación : ls, cd, y pwd
10.1.1 ls
Este comando lista los archivos en un directorio. Los usuarios de Windows y DOS pueden hallarlo similar al comando dir. Por sí solo, ls(1) listará los archivos que se encuentran en el directorio actual. Para ver que hay en su directorio raiz, usted puede ejecutar estos comandos:
% cd / |
El problema que muchas personas tienen con este tipo de salida es que no pueden decir fácilmente qué es un directorio y qué es un archivo. Algunos usuarios prefieren que ls adicione algún tipo de identificador a cada elemento listado, como sigue:
% ls -FC |
Los directorios tienen una barra a la derecha (slash) al final del nombre, los archivos ejecutables tienen un asterisco, y así.
ls también puede ser utilizado para obtener otras estadísticas en los archivos. Por ejemplo, para ver las fechas de creación, propietarios, y permisos, usted debe ejecutar un listado largo:
% ls -l |
Suponga que usted quiere obtener una lista de los archivos ocultos en el directorio actual. Este comando hace precisamente eso:
% ls -a |
Los archivos que comienzan con un punto (llamados archivos punto) se mantienen ocultos cuando usted corre ls. Usted sólo los verá si pasa la opción -a.
Existen muchas más opciones que pueden encontrarse en la página man. No olvide que puede combinar las opciones que le pase a ls.
10.1.2 cd
El comando cd es utilizado para cambiar de directorio de trabajo. Usted simplemente teclee cd seguido del nombre del camino al cual desea cambiarse. A continuación se muestran algunos ejemplos:
darkstar:~$ cd /bin |
Note que sin el slash precedente, este intenta cambiarse de directorio en el directorio actual. cd sin opciones lo llevará a su directorio home.
El comando cd no es como los otros comandos. Es un comando interno de la consola. Los comandos internos de la consola se discuten en la Sección 8.3.1. Esto no debe preocuparle en lo absoluto por ahora. Básicamente significa que este comando no tiene página man. En su lugar, usted debe utilizar la ayuda de la consola, así:
% help cd
|
Esto mostrará las opciones de cd y como utilizarlas.
10.1.3 pwd
El comando pwd es utilizado para mostrar la ubicación actual. Para utilizar el comando pwd sencillamente teclee pwd. Por ejemplo:
% cd /bin |
10.2 Paginadores: more, less, y most
10.2.1 more
more(1) es lo que llamamos una utilidad de paginación. A veces la salida de un comando en particular es muy grande para caber en la pantalla. El comando individual no sabe como poner su salida en pantallas separadas. Le deja el trabajo a la utilidad de paginación.
El comando more divide la salida en pantallas individuales y espera que usted oprima la barra espaciadora antes de continuar con la próxima pantalla. Presionando la tecla Enter avanza la salida una línea. Aquí se muestra un buen ejemplo:
% cd /usr/bin |
Eso debe desenrrollarse durante un rato. Para dividir la salida pantalla a pantalla, solamente condúzcalo hacia more:
% ls -l | more
|
Este es el caracter conducto (shift backslash). El conducto es una abreviatura para decir: toma la salida de ls y alimenta con eso a more. Usted puede conducir casi cualquier cosa a través del comando more , no solamente ls. Los conductos son explicados en la Sección 8.2.3.
10.2.2 less
El comando more es muy manuable, pero a veces sucede que usted ya pasó la pantalla que le interesaba. more no brinda manera de regresar. El comando less(1) brinda esta funcionalidad. Se utiliza de la misma manera que el comando more, así que el ejemplo anterior se aplica aquí también. Entonces, less es más que more. Joost Kremers lo escribió de esta manera:
10.2.3 most
Donde more y less terminan, most(1) comienza. Si less es más que more, most es más que less. Siempre que el resto de los paginadores solamente pueden mostrar un archivo al mismo tiempo, most es capaz de visualizar cualquier número de archivos, siempre y cuando cada ventana de archivo tenga al menos dos líneas de longitud. most tiene muchas opciones, revise la página man para obtener los detalles.
10.3 Salida Simple: cat y echo
10.3.1 cat
cat(1) es una abreviatura para “concatenar”. Fue originalmente diseñado para unir largos archivos en uno solo, pero puede ser utilizado para muchos otros propósitos.
Para unir dos o más archivos en uno, usted simplemente liste los archivos después del comando cat y luego redireccione la salida hacia un archivo. cat funciona con entrada y salida estándar, así que usted tendrá que utilizar los caracteres de redirección de la consola. Por ejemplo:
% cat archivo1 archivo2 archivo3 > granarchivo
|
Este comando toma el contenido de archivo1, archivo2, y archivo3 y los une todos. La nueva salida se envía a la salida estándar.
Uno también puede utilizar cat para mostrar archivos. Muchas personas hacen cat a archivos texto a través de los comandos more o less, así:
% cat archivo1 | more
|
Esto debe mostrar el archivo archivo1 y conducirlo hacia el comando more de manera que usted solamente vea una pantalla a la vez.
Otro uso común de cat es copiar archivos. Usted puede copiar un archivo a donde desee con cat, así:
% cat /bin/bash > ~/mybash
|
El programa /bin/bash es copiado hacia su directorio home y es llamado mybash.
cat tiene tantos usos que estos que hemos discutido aquí son realmente pocos. Como cat hace extensivo el uso de la entrada estándar y la salida estándar, es ideal para ser utilizado en scripts de consola o como parte de otros comandos más complejos.
10.3.2 echo
El comando echo(1) muestra el texto especificado en la pantalla. Usted especifica la cadena a mostrar después del comando echo. Por omisión, echo mostrará la cadena e imprimirá el caracter línea nueva a continuación. La opción -e causará que echo busque caracteres de escape en la cadena y los ejecuta.
10.4 Creación: touch y mkdir
10.4.1 touch
touch(1) es utilizado para cambiar la fecha en un archivo. Usted puede acceder a las fechas y modificarlas con este comando. Si el archivo especificado no existe, touch va a crear un archivo de longitud cero con el nombre de archivo especificado. Para marcar un archivo con la fecha actual, usted debe ejecutar el siguiente comando:
% ls -al archivo1 |
Existen muchas opciones para touch, incluyendo opciones para especificar que fecha modificar, la hora a usar y muchas más. El manual en línea discute estas en detalle.
10.4.2 mkdir
mkdir(1) crea un nuevo directorio. Usted simplemente especifica el directorio a crear cuando usted corre mkdir. Este ejemplo crea el directorio hejaz en el directorio actual:
% mkdir hejaz
|
Usted también puede especificar un camino, así:
% mkdir /usr/local/hejaz
|
La opción -p le dice a mkdir que cree cualquier directorio padre. El ejemplo siguiente fallará si /usr/local no existe. La opción -p creará /usr/local y /usr/local/hejaz:
% mkdir -p /usr/local/hejaz
|
10.5 Copiar y Mover: cp y mv
10.5.1 cp
cp(1) copia archivos. Los usuarios de DOS notarán su similitud con el comando copy. Existen muchas opciones para cp , así que usted tendrá que mirar la página man antes de utilizarlas.
Un uso común de cp es copiar un archivo de un lugar a otro. Por ejemplo:
% cp hejaz /tmp
|
Esta secuencia copia el archivo hejaz del directorio actual al directorio /tmp.
Muchos usuarios prefieren mantener las fechas, como en este ejemplo:
% cp -a hejaz /tmp
|
Esto asegura que las fechas no son modificadas cuando se copien.
Para copiar recursivamente el contenido de un directorio hacia otro directorio, usted debe ejecutar este comando:
% cp -R midirectorio /tmp
|
Esto copiará el directorio midirectorio hacia el directorio /tmp.
También, si usted desea copiar un directorio o un archivo y mantener sus permisos y fecha como estaban, use cp -p.
% ls -l archivo |
cp tiene muchas más opciones que se discuten en detalle en las páginas man.
10.5.2 mv
mv(1) mueve archivos de un lugar a otro. ¿Suena sencillo, no?
% mv viejoarchivo /tmp/nuevoarchivo
|
mv tiene unas cuantas opciones útiles que se detallan en las páginas man. En la práctica, mv casi nunca es utilizado con opciones.
10.6 Eliminación: rm y rmdir
10.6.1 rm
rm(1) elimina archivos y árboles de directorio. Los usuarios de DOS notarán similaridades con los comandos del y deltree. rm puede ser muy peligroso si usted no se mantiene vigilado. Aunque a veces es posible salvar un fichero ya borrado, puede ser complicado, (y potencialmente caro) y está fuera del alcance de este libro.
Para eliminar un solo archivo, especifique su nombre cuando corra rm:
% rm archivo1
|
Si el archivo tiene eliminados los permisos de escritura, usted obtendrá un error de denegación de permisos. Para obligar la eliminación de archivos sin importar esto, pase la opción -f, así:
% rm -f archivo1
|
Para eliminar un directorio completo, use conjuntamente las opciones -r y -f . Este es un buen ejemplo de como eliminar todo el contenido de su disco duro. Usted realmente no quiere hacer eso. Pero aquí va el comando:
# rm -rf /
|
Tenga cuidado con rm; usted puede dispararse en sus propios pies. Existen muchas opciones de línea de comandos, las cuales se discuten en detalle en la página man.
10.6.2 rmdir
rmdir(1) elimina directorios del sistema de archivos. El directorio debe estar vacío antes de ser eliminado. La sintaxis es simplemente:
% rmdir <directorio>
|
Este ejemplo va a eliminar el subdirectorio hejaz en el directorio de trabajo actual:
% rmdir hejaz
|
Si este directorio no existe, rmdir se lo dirá. Usted también puede especificar un camino completo hacia el directorio a eliminar, como muestra este ejemplo:
% rmdir /tmp/hejaz
|
Este ejemplo intentará eliminar el directorio hejaz dentro del directorio /tmp.
Usted puede además eliminar un directorio y todo sus directorios padres pasando la opción -p.
% rmdir -p /tmp/hejaz
|
Esto primero intentará eliminar el directorio hejaz dentro de /tmp. Si esto es exitoso, esto intentará eliminar /tmp. rmdir continuará hasta que encuentre un error o hasta que todo el camino especificado haya sido eliminado.
10.7 Haciendo Alias a Archivos con ln
ln(1) es utilizado para crear enlaces entre archivos. Estos enlaces pueden ser enlaces fuertes o débiles (simbólicos). Las diferencias entre estos dos tipos de enlaces fueron discutidas en la Sección 9.3. Si usted desea hacer un enlace simbólico al directorio /var/media/mp3 y ponerlo en su directorio home, se hace así:
% ln -s /var/media/mp3 ~/mp3
|
La opción -s le dice a ln que haga un enlace simbólico. La próxima opción es el blanco del enlace, y la opción final es el lugar donde poner el enlace. En este caso, esto solamente va a crear un archivo llamado mp3 en su directorio home, que apunta a /var/media/mp3. Usted puede llamar al enlace por sí mismo con el nombre que desee sencillamente cambiando la última opción.
Crear un enlace fuerte es igual de simple. Todo lo que usted tiene que hacer es abandonar la opción -s. Los enlaces fuertes normalmente no se refieren a directorios o a sistemas de archivos. De cualquier manera, para crear un enlace fuerte de /usr/bin/email a /usr/bin/mutt, simplemente teclee lo siguiente:
# ln /usr/bin/mutt /usr/bin/email
|
Capítulo 11 Control de Procesos
11.1 Pasando a Segundo Plano
Los programas iniciados desde la línea de comandos arrancan en primer plano. Esto le permite a usted ver la salida del programa e interactuar con él. Pero en muchas ocasiones usted desearía que el programa corriera sin bloquearle el terminal. Esto se realiza pasando al programa a un segundo plano, y hay varias formas de hacerlo.
La primera forma de pasar a segundo plano a un proceso es adicionando un ampersand (&) a la línea de comandos cuando usted arranque el programa. Por ejemplo, asumamos que usted desea utilizar el programa de línea de comandos para reproducir mp3 amp para reproducir un directorio lleno de mp3s, pero usted necesita hacer algo más en el mismo terminal. La siguiente línea de comandos arrancará amp en segundo plano:
% amp *.mp3 &
|
El programa correrá como es normal, y a usted se le devuelve el prompt.
La otra manera de pasar a segundo plano un proceso es hacerlo mientras está corriendo. Primero, arranque el programa. Mientras está corriendo, oprima Control+z. Esto suspende el proceso. Un proceso suspenso es básicamente pausado. Este se detiene momentáneamente, pero puede ser iniciado de nuevo en cualquier otro momento. Una vez que usted haya suspendido el proceso, se le devuelve el prompt. Usted puede mandar a segundo plano este proceso tecleando:
% bg
|
Ahora el proceso suspendido está corriendo en segundo plano.
11.2 Pasando a Primer Plano
Si usted necesita interactuar con un proceso en segundo plano, usted puede traerlo de vuelta al primer plano. Si usted solamente tiene un proceso en segundo plano, puede traerlo a primer plano tecleando:
% fg
|
Si el programa no ha terminado de correr, el programa tomará el control sobre su terminal y a usted no le será devuelto el prompt. A veces, el programa va a terminar de correr mientras está en segundo plano. En ese caso, usted obtendrá un mensaje como este:
[1]+ Done /bin/ls $LS_OPTIONS |
Que le dice que el proceso en segundo plano (en este caso ls - no es terriblemente interesante) ha terminado.
Es posible tener muchos procesos en segundo plano al mismo tiempo. Cuando esto sucede, usted necesita saber qué proceso desea traer al primer plano. Si teclea solamente fg traerá a primer plano el último proceso que mandó a segundo plano. ¿Y qué sucede si usted tiene toda una lista de procesos en segundo plano? Afortunadamente bash incluye un comando para listar todos los procesos. Se llama jobs y su salida es similar a esta:
% jobs |
Este muestra una lista de todos los procesos que están en segundo plano. Como usted puede observar, todos están detenidos. Esto significa que todos los procesos están suspendidos. El número es una especie de identificador de procesos en segundo plano. El identificador con un signo de más después del número (man ps) es el proceso que va a ser traído a primer plano si se teclea solamente fg.
Si usted quiere traer a primer plano vim, usted debe teclear:
% fg 1
|
y vim debe retornar a su consola. Pasar a segundo plano procesos puede ser muy útil si usted solamente tiene un terminal a través de una línea telefónica. Usted puede tener varios programas corriendo en ese terminal, y periódicamente ir a uno u otro.
11.3 ps
Ahora que usted conoce como llevar y traer varios procesos que usted ha iniciado desde la línea de comandos, y que conoce que hay muchos procesos corriendo al mismo tiempo, se preguntará ¿Cómo obtener una lista de todos estos programas? Bien, para eso se utiliza el comando ps(1). Este comando tiene muchas opciones, así que aquí trataremos solamente las más importantes. Para obtener una lista completa, vea la página man de ps. Las páginas man se comentan en profundidad en la Sección 2.1.1.
Simplemente tecleando ps, usted obtendrá una lista de los programas que se encuentran corriendo en su terminal. Esto incluye los procesos en primer plano (lo cual incluye hasta la consola que usted está usando, y por supuesto, ps en sí). También se muestran los procesos que estén en segundo plano. Muchas veces, la lista será muy corta:
Figura 11-1. Salida del comando ps
% ps -ax |
Si usted quiere obtener más información sobre los procesos que están corriendo, pruebe esto:
% ps -aux |
11.4 kill
En ciertas ocasiones, los programas se comportan incorrectamente y usted necesita regresarlos a la línea. El programa para esa clase de administración se llama kill(1), y puede ser utilizado para manipular procesos de diversas maneras. El uso más obvio de kill es matar un proceso. Usted necesitará hacer eso si un programa se ha disparado y está utilizando muchos recursos del sistema, o sencillamente si usted está cansado de verlo correr.
Para matar un proceso, usted necesitará conocer su PID o su nombre. Para obtener el PID, use el comando ps como fue discutido en la sección anterior. Por ejemplo, para matar el proceso 4747, usted debe utilizar lo siguiente:
% kill 4747
|
Note que usted debe ser el propietario del proceso para poder matarlo. Esto es por razones de seguridad. Si a usted se le permitiera matar los procesos que iniciaran otros usuarios, sería posible hacer muchas cosas maliciosas. Por supuesto, root puede matar cualquier proceso del sistema.
Existe otra variedad del comando kill llamado killall(1). Este programa hace exactamente lo que dice: mata todos los procesos que tienen determinado nombre. Si usted desea matar todos los procesos vim que están corriendo, usted podría teclear el siguiente comando:
% killall vim
|
Cualquiera y cada uno de los procesos vim que usted tenga corriendo morirán. Haciendo esto como root matará todos los procesos vim que estén corriendo cualquiera de los usuarios. Lo siguiente muestra una interesante manera de sacar a patadas a todo el mundo (incluyéndolo a usted) del sistema:
# killall bash
|
A veces un kill normal no hace bien el trabajo. Ciertos procesos no morirán con un kill. Usted necesitará una manera más potente. Si ese irritante PID 4747 no ha estado respondiendo a su solicitud de kill, usted puede hacer lo siguiente:
% kill -9 4747
|
Esto casi seguro que causará que el proceso 4747 muera. Usted puede hacer la misma cosa con killall. Lo que estamos haciendo con esto es mandando una señal diferente al proceso. Un kill normal manda una señal SIGTERM (terminar) al proceso, el cual le pide que termine lo que está haciendo, limpie y salga. kill -9 manda una señal SIGKILL (matar) al proceso, la cual esencialmente lo elimina. A este proceso no se le permite que limpie, y a veces pueden ocurrir cosas malas si se utiliza SIGKILL, como corrupción de datos, por ejemplo. Existe toda una lista de señales a su disposición. Usted puede obtener una lista de señales tecleando lo siguiente:
% kill -l |
El número debe ser utilizado para kill, mientras que el nombre sin el prefijo “SIG” puede ser utilizado con killall. He aquí otro ejemplo:
% killall -KILL vim
|
Un último uso de kill es para reiniciar un proceso. Mandando una señal SIGHUP causará que la mayoría de los procesos relean sus archivos de configuración. Esto es especialmente útil para decirle a los procesos del sistema que relean sus archivos de configuración después de haber sido editados.
11.5 top
Finalmente, existe un comando que usted puede utilizar para mostrar información actualizada sobre los procesos que están corriendo en el sistema. Este comando es llamado top(1), y se inicia así:
% top
|
Esto mostrará una pantalla llena de información sobre los procesos corriendo en el sistema, así como ciertas informaciones genéricas del sistema. Esto incluye carga promedio, número de procesos, estado de la CPU, información de memoria libre, y detalles sobre los procesos que incluyen PID, usuario, prioridad, información de uso de memoria y CPU, tiempo que lleva corriendo, y nombre del programa.
6:47pm up 1 day, 18:01, 1 user, load average: 0.02, 0.07, 0.02 |
Se llama top porque los procesos de uso más intensivo de la CPU se muestran arriba (top). Una nota interesante es que top se mostrará primero en sistemas mayormente inactivos (y algunos activos) debido a su utilización de la CPU. De cualquier forma, top es muy útil para determinar que programa se está comportando incorrectamente y necesita ser muerto.
Pero suponga que usted solamente necesita una lista de sus propios procesos, o de los procesos de otro usuario. Los procesos que usted desea ver puede que no sean los de uso más intensivo de la CPU. La opción -u le permite a usted especificar el nombre de usuario o UID y monitorear solamente aquellos procesos que sean propiedad de ese UID.
% top -u alan |
Como usted puede ver, yo estoy actualmente corriendo X, top, un gnome-terminal (en el cual estoy escribiendo esto) y muchos otros procesos relacionados con X que toman la mayor parte de mi tiempo de CPU. Esta es una buena manera de monitorear cuan fuertemente sus usuarios están utilizando su sistema.
top también soporta monitoreo de procesos por su PID, ignorar procesos ociosos y zombies, y muchas otras opciones. El mejor lugar para obtener estas opciones es la página man de top.
Capítulo 12 Administración Básica del Sistema
12.1 Usuarios y Grupos
Como mencionamos en el Capítulo 8, usted no debe utilizar normalmente su sistema con la sesión de root. En su lugar, usted debe crear una cuenta de usuario normal para uso diario, y utilizar la cuenta root solamente para tareas de administración. Para crear un usuario, usted puede utilizar las herramientas que le brinda Slackware, o puede editar los archivos de contraseñas a mano.
12.1.1 Scripts Brindados
La manera más sencilla de gestionar usuarios y grupos es con los scripts y programas que se brindan. Slackware incluye los programas adduser, userdel(8), chfn(1), chsh(1), y passwd(1) para tratar con los usuarios. Los comandos groupadd(8), groupdel(8), y groupmod(8) son para trabajar con los grupos. Con la excepción de chfn, chsh, y passwd, estos programas solamente pueden ser ejecutados como root, y por ende se encuentran en /usr/sbin. chfn, chsh, y passwd puede ser ejecutado por cualquier usuario, y se encuentran en /usr/bin.
Los usuarios pueden ser adicionados con el programa adduser. Comenzaremos pasando a través de todo el procedimiento, mostrando todas las preguntas que se hacen y una breve descripción de lo que significa cada cosa. Las respuestas por omisión se encuentran entre corchetes, y pueden ser seleccionadas para casi todas las preguntas, a menos que usted de veras desee cambiar algo.
# adduser |
Este es el nombre que el usuario utilizará para iniciar sesión. Tradicionalmente, los nombres de inicio de sesión tienen ocho caracteres o menos, y todos en minúsculas. (Usted puede utilizar más de ocho caracteres, o dígitos, pero trate de no hacer eso a menos que tenga una razón verdaderamente importante).
Usted puede además brindar el nombre de usuario como argumento en la línea de comandos:
# adduser jellyd
|
En cualquiera de los casos, después de brindar el nombre de inicio de sesión, adduser le preguntará el ID de usuario:
User ID ('UID') [ defaults to next available ]:
|
El ID de usuario (UID) dice como las propiedades se determinan realmente en Linux. Cada usuario tiene un único nombre, comenzando por 1000 en Slackware. Usted puede seleccionar una UID para el nuevo usuario, o puede dejar que adduser asigne el próximo identificador de usuario que esté libre.
Initial group [users]: |
Todos los usuarios son situados en el grupo users por omisión. Usted puede que desee poner el nuevo usuario en un grupo diferente, pero esto no es recomendado a menos que usted sepa lo que está haciendo.
Additional groups (comma separated) []: |
Esta pregunta permite poner al nuevo usuario en grupos adicionales. Es posible que un usuario esté en múltiples grupos al mismo tiempo. Esto es útil si usted ha establecido grupos para cosas tales como modificar los archivos de un sitio web, jugar, y otras. Por ejemplo, algunos sitios definen en grupo wheel como el único grupo que puede utilizar el comando su. O, una instalación por omisión de Slackware utiliza el grupo sys para aquellos usuarios que están autorizados a emitir sonidos mediante la tarjeta de sonido interna.
Home directory [/home/jellyd] |
Los directorios home por omisión se sitúan bajo /home. Si usted está corriendo un sistema muy grande, es posible que usted haya movido los archivos home a otro lugar (o hacia otros lugares). Este paso le permite especificar donde estará el directorio home del usuario.
Shell [ /bin/bash ] |
bash es el intérprete de comandos por omisión de Slackware Linux, y estará bien para la mayoría de las personas. Si sus usuarios tienen conocimientos de Unix, tal vez se sientan más a gusto con otro intérprete de comandos. Usted puede cambiar su intérprete de comandos ahora, o lo pueden cambiar ellos más tarde mediante el comando chsh.
Expiry date (YYYY-MM-DD) []: |
Las cuentas pueden ser configuradas para que venzan en una fecha especificada. Por omisión, no tienen fecha de vencimiento. Usted puede cambiar eso, si lo desea. Estas opciones pueden ser útiles para las personas que mantienen un ISP (Proveedor de Servicios de Internet) que necesiten que determinada cuenta venza en determinada fecha, a menos que reciban el pago por el año próximo.
New account will be created as follows: |
Esto es todo... si usted desea catapultarse, oprima Control+C. Si no, presione ENTER para continuar y crear la cuenta.
En este momento verá toda la información que usted ha entrado sobre la nueva cuenta y se le brindará la oportunidad de cancelar la creación de la cuenta. Si entró algún dato incorrectamente, usted debe oprimir Control+C y comenzar de nuevo. De otra forma, usted puede oprimir enter y la cuenta será creada.
Creating new account... |
Toda esa información es opcional. Usted no tiene que entrar ninguno de estos datos si no lo desea, y el usuario puede cambiarlos cuando lo desee mediante chfn. Aunque usted puede encontrar útil entrar al menos el nombre completo y el número telefónico, en caso que necesite mantenerse en contacto con la persona.
Changing password for jellyd |
Usted tiene que entrar una contraseña para el nuevo usuario. Generalmente, si el nuevo usuario no se encuentra presente en ese momento, usted sencillamente seleccione cualquier contraseña por omisión, y pídale al usuario que la cambie por otra más segura.
|
Seleccionando una contraseña: Tener una contraseña segura es la primera línea de defensa contra ser penetrado. Usted no debe tener una contraseña fácil de averiguar, ya que esto facilita el trabajo de la persona que desee entrar en su sistema. Idealmente, una contraseña segura será una cadena aleatoria de caracteres, incluyendo letras mayúsculas y minúsculas, números y caracteres aleatorios. (El caracter Tab no debe ser una opción inteligente, en dependencia de la clase de computadora desde la cual está iniciando sesión). Existen varios paquetes de software que generan contraseñas seguras para usted; busque en Internet para obtener estas utilidades. En general, use el sentido común: no seleccione una contraseña que sea el cumpleaños de alguien, una frase común, algo que esté escrito en su escritorio, o cualquier otra cosa que se relacione con usted. Una contraseña como “segura1” o cualquier otra contraseña que usted vea impresa o en Internet también es mala. |
Eliminar usuarios no es para nada difícil. Solamente ejecute userdel con el nombre de usuario de la cuenta que desea eliminar. Usted debe verificar que el usuario no se encuentre en medio de una sesión, y que ningún proceso esté corriendo con ese usuario. También, recuerde que una vez que usted haya eliminado este usuario, toda la información relativa a la contraseña del usuario es eliminada permanentemente
# userdel jellyd
|
Este comando elimina ese molesto usuario jellyd de su sistema. ¡Hasta la vista! :) El usuario es eliminado de los archivos /etc/passwd, /etc/shadow, y /etc/group, pero no se elimina el directorio home del usuario.
Si usted quiere eliminar el directorio home también, debe en su lugar utilizar este comando:
# userdel -r jellyd
|
Deshabilitar una cuenta temporalmente será explicado en la próxima sección, ya que este cambio trae consigo un cambio de contraseña del usuario. Cambiar otras informaciones de la cuenta es cubierto en la Sección 12.1.3.
Los programas para adicionar y eliminar grupos son muy simples. groupadd sencillamente creará otra entrada en el archivo /etc/group con una única ID de grupo, mientras que groupdel eliminará el grupo especificado. Queda como opción para usted editar /etc/group para adicionar usuarios a un grupo en específico. Por ejemplo, para adicionar un grupo llamado cvs:
# groupadd cvs
|
Y para eliminarlo:
# groupdel cvs
|
12.1.2 Cambiando Contraseñas
El programa passwd cambia las contraseñas modificando el archivo /etc/shadow. Este archivo guarda todas las contraseñas del sistema en un formato encriptado. Para cambiar su propia contraseña, usted debe teclear:
% passwd |
Como puede observar, se le pide que entre la contraseña anterior. Esta no va a aparecer en pantalla cuando la teclee, al igual que sucede cuando inicia sesion. Entonces, se le pide que entre la nueva contraseña. passwd realiza chequeos con su nueva contraseña, y se quejará si su nueva contraseña no cumple los requerimientos. Usted puede ignorar estas precauciones si lo desea. Se le pedirá que introduzca su contraseña una vez más para confirmar.
Si usted es root, puede además cambiar la contraseña de otro usuario:
# passwd ted
|
Entonces tendrá que seguir el mismo procedimiento anteriormente mencionado, excepto que no tendrá que entrar la contraseña anterior. (Uno de los tantos beneficios de ser root...)
Si necesita, usted puede también deshabilitar una cuenta temporalmente, y rehabilitarla posteriormente, si lo necesita. Tanto habilitar una cuenta como deshabilitarla puede ser hecho con passwd. Para deshabilitar una cuenta, teclee lo siguiente como root:
# passwd -l david
|
Esto cambiará la contraseña de david por una que nunca coincidirá con ningún valor encriptado. Puede rehabilitar la cuenta utilizando:
# passwd -u david
|
Ahora, la cuenta de david retorna a la normalidad. Deshabilitar una cuenta puede ser útil si un usuario no está siguiendo las reglas que usted ha impuesto, o si ha exportado demasiadas copias de xeyes(1) a su escritorio X.
12.1.3 Cambiando la Información de Usuario
Hay dos componentes de la información que los usuarios pueden cambiar en cualquier momento: su intérprete de comandos y su información de contacto. Slackware Linux usa chsh (change shell) y chfn (change finger) para modificar estos valores respectivamente.
Un usuario puede seleccionar cualquier intérprete de comandos de los que se encuentran en el archivo /etc/shells. Para la mayoría de las personas, /bin/bash estará bien. Otros pueden sentirse mejor con el intérprete que está en sus sistemas en la escuela, o en el trabajo, y quieren usar lo que ya ellos conocen. Para cambiar su intérprete de comandos, use chsh:
% chsh |
Después de entrar su contraseña, entre el camino completo hasta el nuevo intérprete. Asegúrese primero de que esté listado en el archivo /etc/shells(5). El usuario root puede también cambiar la consola de cualquier usuario, ejecutando chsh con el nombre de usuario como argumento.
La información de contacto es información opcional, como por ejemplo nombre completo, números telefónicos, y número de habitación. Esta puede ser cambiada utilizando chfn, y siguiendo el mismo procedimiento que se utilizó para la creación de la cuenta. Como es usual, root puede cambiar la información de contacto de cualquier otro usuario.
12.2 Usuarios y Grupos, La Manera Difícil
Por supuesto, es posible adicionar, modificar y eliminar usuarios y grupos sin utilizar los scripts y programas que vienen con Slackware. Realmente no es difícil, aunque puede que después de leer este procedimiento, usted encuentre mucho más fácil utilizar los scripts. De cualquier manera, es importante saber como se almacena su contraseña, en caso de que necesite recuperar esa información y no tenga a mano las herramientas de Slackware.
Primero, adicionaremos el nuevo usuario a los archivos /etc/passwd(5), /etc/shadow(5), y /etc/group(5). El archivo passwd guarda alguna información sobre los usuarios en su sistema, pero (qué extraño) no almacena las contraseñas. Hace mucho tiempo atrás los guardaba, pero por razones de seguridad ya no se guardan ahí. El archivo passwd debe ser legible por todos los usuarios, y para los posibles intrusos, era posible utilizar los archivos encriptados como punto de comienzo para desencriptar la contraseña de los usuarios. En su lugar, las contraseñas encriptadas se guardan en el archivo shadow, el cual es solamente legible por root, y las contraseñas del resto de los usuarios se almacena en el archivo passwd simplemente como “x”. El archivo group lista todos los grupos y quién está en cada uno.
Usted puede utilizar el comando vipw para editar el archivo /etc/passwd con seguridad, y el comando vigr para editar el archivo /etc/group con seguridad. Use vipw -s para editar el archivo /etc/shadow con seguridad. (“con seguridad” en este contexto significa que nadie más podrá editar el archivo que usted está editando en ese momento. Si usted es el único administrador de su sistema, probablemente no haya problemas, pero es mejor crear los buenos hábitos desde el comienzo).
Examinemos el archivo /etc/passwd y veamos como adicionar un nuevo usuario. Una línea típica de passwd luce así:
chris:x:1000:100:Chris Lumens,Room 2,,:/home/chris:/bin/bash |
Cada línea es una entrada para un usuario, y los campos de una línea están separados por dos puntos (:). Los campos son nombre de usuario, contraseña encriptada (“x” para todo el mundo en sistemas Slackware, pues Slackware guarda las contraseñas en shadow), identificador de usuario (user ID), identificador de grupo (group ID), la información de contacto opcional (separada por comas), el directorio home, y el intérprete de comandos. Para adicionar un usuario a mano, adicione una nueva línea al final del archivo, con la información apropiada.
La información que usted inserte debe cumplir ciertos requerimientos, o su nuevo usuario puede tener problemas para iniciar sesión. Primero, asegúrese de que en el campo contraseña haya una x, y que tanto el nombre de usuario como el identificador de usuario son únicos. Asigne un grupo al usuario, puede ser 100 (el grupo “users” en Slackware) o su grupo por omisión (use su número, no su nombre). Dele al usuario un directorio home válido (el cual usted creará posteriormente) y un intérprete de comandos (recuerde, los válidos se encuentran en /etc/shells).
A continuación, usted necesitará adicionar una entrada en el archivo /etc/shadow, el cual guarda las contraseñas encriptadas. Una entrada típica luce así:
chris:$1$w9bsw/N9$uwLr2bRER6YyBS.CAEp7R.:11055:0:99999:7::: |
De nuevo, cada línea es una entrada para una persona, con cada campo delimitado por dos puntos (:). Los campos son (en orden) nombre de usuario, contraseña encriptada, días desde la Época (1ro. de Enero de 1970) en el cual la contraseña fue cambiada por última vez, días antes de que la contraseña deba ser cambiada, días después de los cuales la contraseña debe ser cambiada, días antes del vencimiento de la contraseña en los cuales el usuario debe ser notificado, días después del vencimiento que la cuenta debe ser deshabilitada, días desde la Época en que la cuenta se ha deshabilitado, y campo reservado.
Como puede observar, la mayoría de la información es concerniente al vencimiento de la sesión. Si usted no está utilizando información de vencimiento de sesiones, usted solamente necesitará llenar los nuevos campos con algunos valores especiales. Si la está utilizando, en cambio, necesitará hacer ciertos cálculos antes de que pueda llenar los campos. Para un nuevo usuario, sencillamente ponga basura aleatoria en el campo contraseña. No se preocupe sobre lo que significa lo que ha tecleado, porque sea lo que sea lo cambiará en cuestión de minutos. El único caracter que usted no puede incluir en el campo contraseña es los dos puntos (:). Deje el campo “días desde que la contraseña fue cambiada” también en blanco. Luego ponga 0, 99999, y 7 como mismo ve en la entrada del ejemplo, y deje el resto de los campos en blanco.
(Para aquellos que piensan que han visto mi contraseña encriptada en el ejemplo de arriba y creen que tienen la primera pista para irrumpir en mi sistema, adelante. Si pueden desencriptar esta contraseña, sabrán la contraseña de un sistema de prueba con cortafuegos. Ahora sí es útil :) )
Todos los usuarios normales son miembros del grupo “users” en un sistema típico Slackware. Aunque, si usted desea crear un nuevo grupo, necesitará modificar el archivo /etc/group. He aquí una entrada típica:
cvs::102:chris,logan,david,root |
Los campos son nombre del grupo, contraseña del grupo, identificador de grupo y miembros del grupo, separados por comas. Crear un nuevo grupo es solamente adicionar una nueva línea con un identificador de grupo único, y una lista de los usuarios que usted desee incluir en el grupo. Cualquier usuario que esté en este nuevo grupo y se encuentre en medio de una sesión, necesitará cerrar la sesión e iniciar una nueva para que los cambios se hagan efectivos.
En este punto, es una buena idea utilizar los comandos pwck y grpck para verificar que los cambios que usted ha hecho son consistentes. Primero, utilice pwck -r y grpck -r: el selector -r no realiza cambios, pero dice los cambios que se harían si se corriera el comando sin el selector. Usted puede utilizar la salida de este comando para decidir si necesita modificar más adelante otro archivo, para correr pwck o grpck sin el selector -r, o simplemente para dejar sus cambios como están.
Ahora, debe utilizar el comando passwd para crear una contraseña coherente para el usuario. Entonces, utilice mkdir para crear el directorio home del usuario en el lugar que usted declaró en el archivo /etc/passwd, y usar chown para cambiar el dueño del nuevo directorio, en favor del nuevo usuario.
Eliminar un usuario es tan sencillo como eliminar todas las entradas que existan relativas a ese usuario. Eliminar la entrada del usuario en los archivos /etc/passwd y /etc/shadow, y eliminar el nombre de usuario de cualquier grupo en el archivo /etc/group. Si usted desea, elimine el directorio home del usuario, el archivo de hilos de correo, y sus entradas en crontab (si existen).
Eliminar grupos es similar: Elimine la entrada del grupo en el archivo /etc/group.
12.3 Apagando Adecuadamente
Es muy importante que usted apague su sistema adecuadamente. Apagar simplemente presionando el interruptor puede causar graves daños a su sistema de archivos. Cuando el sistema está funcionando, hay archivos en uso aunque no estemos haciendo nada. Recuerde que hay muchos procesos corriendo en segundo plano todo el tiempo. Estos procesos están gestionando el sistema y manteniendo muchos archivos abiertos. Cuando el sistema es apagado directamente mediante el interruptor, estos archivos no se cierran adecuadamente, y pueden corromperse. En dependencia de los archivos que hayan sido dañados, el sistema puede quedar totalmente inutilizable. En cualquiera de los casos, usted necesitará pasar por un largo proceso de chequeo del sistema de archivos cuando el sistema reinicie.
|
Si usted configuró el sistema con un sistema de archivos tipo "journalling", como por ejemplo ext3 o reiserfs, usted estará parcialmente protegido del daño a su sistema de archivos, y la revisión del sistema al inicio será más corta que si utilizara un sistema de archivos como ext2. De cualquier manera, ¡esto no es justificación para apagar el sistema incorrectamente! Un sistema de archivos tipo "journalling" se supone que proteja sus archivos de eventos que suceden fuera de su control, no de su propia vagancia. |
En cualquiera de los casos, cuando usted desee reiniciar o apagar su computadora, es importante hacerlo adecuadamente. Existen muchas maneras de hacerlo; usted puede seleccionar la que más le agrade (o la que menos trabajo le cause). Como apagar y reiniciar son procesos similares, la mayoría de las vías que se ofrecen para apagar el sistema pueden ser aplicadas para reiniciarlo.
El primer método es mediante el programa shutdown(8), y es probablemente el más popular. shutdown puede ser utilizado para reiniciar o apagar el sistema en cualquier momento dado, y puede mostrar un mensaje a todos los usuarios con sesiones iniciadas en el sistema diciéndoles que el sistema va a apagarse.
El uso más básico de shutdown para apagar la computadora es:
# shutdown -h now
|
En este caso, no mandaremos ningún mensaje personalizado a los usuarios; ellos van a ver el mensaje por omisión de shutdown. “now” (ahora) es el tiempo en el cual deseamos que se apague el sistema, y el “-h” significa que queremos detener el sistema. Esta línea no es muy amistosa cuando se corre en un sistema multiusuario, pero funciona bien en su propia computadora. Un mejor método para los sistemas multiusuarios es darle a los usuarios un poquito de tiempo:
# shutdown -h +60
|
Esto va a apagar el sistema en una hora (60 minutos), lo cual es razonable en un entorno multiusuario común. Los sistemas vitales deben tener su tiempo de apagado planificado con mucho tiempo de antelación, y usted debe mandar avisos sobre el tiempo que planifica tener la computadora apagada en los lugares apropiados que se utilizan para las notificaciones del sistema (correo electrónico, murales, /etc/motd, en cualquier otro lugar).
Reiniciar el sistema utiliza el mismo comando, pero sustituyendo “-r” por “-h”:
# shutdown -r now
|
Usted puede utilizar la misma notación de tiempo que usa con shutdown -h con shutdown -r. Existen muchas otras cosas que usted puede hacer con shutdown para controlar cuando apagar o reiniciar la máquina; vea las páginas man para obtener más información.
La segunda manera de apagar el sistema o la computadora es utilizando los comandos halt(8) y reboot(8). halt detiene inmediatamente el sistema operativo, y reboot reinicia el sistema (reboot es realmente un enlace simbólico a halt.) Estos se invocan así:
# halt |
Una manera de más bajo nivel para reiniciar o apagar el sistema es hablar directamente con init. Todos los otros métodos son simplemente maneras convenientes de hablar con init, pero usted puede directamente decirle que hacer usando telinit(8) (note que solamente tiene una “l”). telinit le dice a init a qué nivel (runlevel) debe pasar, lo cual causa que corra un script especial. Este script matará o creará procesos en la medida en que se necesiten en dicho runlevel. Esto también se aplica para reiniciar y apagar, ya que estos son niveles especiales.
# telinit 0
|
Runlevel 0 es modo apagado. Decirle a init que entre en el runlevel 0 causará que todos los procesos se maten, se desmonten los sistemas de archivos, y la máquina se detenga. Esta es una manera perfectamente aceptable de apagar el sistema. En muchas portátiles y sistemas de escritorio modernos, también apagará físicamente la máquina.
# telinit 6
|
Runlevel 6 es modo reinicio. Todos los procesos se matan, los sistemas de archivo se desmontan, y la máquina se reinicia. Este es un método perfectamente aceptable para reiniciar el sistema.
Para los curiosos, cuando se cambia a runlevel 0 o 6, ya sea mediante shutdown, halt, o reboot, se ejecuta el script /etc/rc.d/rc.6. (El script /etc/rc.d/rc.0 es otro enlace simbólico, a /etc/rc.d/rc.6.) Usted puede personalizar este archivo a su gusto--¡pero asegúrese de probar sus cambios cuidadosamente!
Existe un último método para reiniciar el sistema. El resto de los métodos requieren que usted tenga su sesión iniciada como root, aunque es posible reiniciar la máquina incluso si usted no es root, siempre que tenga acceso físico al teclado. Usar Control+Alt+Delete (el "saludo de tres dedos") causará que la máquina reinicie inmediatamente (Por detrás del telón, se llama al comando shutdown) El saludo no siempre funciona en X Windows--Usted puede que necesite usar Control+Alt+F1 (u otra tecla de Función) para cambiarse a un terminal no-X Windows antes de intentar usarlo.
Por último, el archivo que controla todos los aspectos del inicio y el apagado es archivo /etc/inittab(5). En general, usted no debe necesitar modificar este archivo, pero puede ser que este le de una idea de porqué las cosas funcionan como funcionan. Como siempre, vea las páginas man para obtener más detalles.
Capítulo 13 Comandos Básicos de Red
13.1 ping
ping(8) manda un paquete tipo ICMP ECHO_REQUEST a un host especificado. Si el host responde, usted recibe de él un paquete ICMP. ¿Suena extraño? Bueno, usted puede hacerle “ping” a una dirección IP para ver si una máquina está viva. Si no responde, ya sabe que algo malo está pasando. He aquí una conversación de ejemplo entre dos usuarios de Linux:
Usuario A: Loki se cayó otra vez.
Usuario B: ¿Estás seguro?
Usuario A: Sip, traté de hacerle ping, pero no responde.
% ping www.slackware.com |
13.2 traceroute
El comando traceroute(8) de Slackware es muy útil como herramienta de diagnóstico. traceroute muestra a través de qué hosts viaja el paquete mientras intenta llegar a su destino. Usted puede ver a cuantos “saltos” se encuentra del sitio web de Slackware con este comando:
% traceroute www.slackware.com |
Cada host será mostrado, junto con los tiempos de respuesta de cada uno. A continuación, un ejemplo:
% traceroute www.slackware.com |
traceroute es similar a ping, pues utiliza paquetes ICMP. Existen muchas opciones que usted puede especificarle a traceroute. Estas opciones se explican en detalle en la página man.
13.3 Herramientas DNS
Domain Name Service (Servicio de Nombres de Dominio, DNS para abreviar) es el protocolo mágico que le permite a su computadora convertir nombres de dominio sin significado como www.slackware.com en direcciones IP con significado, como 64.57.102.34. Las computadoras no pueden enrutar paquetes hacia www.slackware.com, en cambio, pueden enrutar paquetes hacia la dirección IP correspondiente con ese nombre de dominio. Esto nos brinda una manera conveniente de recordar las máquinas. Sin DNS tendríamos que tener una base de datos mental solamente para recordar que dirección IP corresponde con qué máquina, asumiendo que la dirección IP no cambie. Claramente, usar nombres para las computadoras es mejor, ¿Pero como convertimos nombres en direcciones IP?
13.3.1 host
host(1) puede hacerlo. host se utiliza para transformar los nombres en direcciones IP. Es una utilidad muy simple y rápida, sin tantas funcionalidades.
% host www.slackware.com |
Pero digamos que por alguna razón deseamos averiguar que nombre tiene determinada dirección IP. ¿Qué hacer entonces?
13.3.2 nslookup
nslookup es un programa probado que ha desafiado las eras. nslookup ha sido descontinuado y puede ser eliminado de versiones futuras. Este programa no tiene ni siquiera página man.
% nslookup 64.57.102.34 |
13.3.3 dig
El perro más cruel de la perrera, el acosador de la información de dominio, dig(1) para abreviar, es el programa al cual acudir para buscar información DNS. dig puede obtener casi todo de un servidor DNS, incluyendo búsquedas inversas, y registros A, CNAME, MX, SP, y TXT. dig tiene muchas opciones desde la línea de comandos y si no le es familiar debe leerse una extensa página man.
% dig @192.168.1.254 www.slackware.com mx |
Esto debe darle una idea de como funciona dig. “@192.168.1.254” especifica el servidor dns que debe usar. “www.slackware.com” es el nombre de dominio sobre el cual estoy averiguando, y “mx” es el tipo de averiguación que estoy haciendo. La consulta anterior me dice que el correo electrónico que se mande a www.slackware.com será enviado a mail.slackware.com para que sea entregado.
13.4 finger
finger(1) obtendrá información sobre el usuario especificado. Usted le brinda a finger un nombre de usuario o una dirección de correo electrónico, y este intentará contactar el servidor necesario y obtener información sobre el usuario especificado, como nombre de usuario, oficina, número telefónico y otras informaciones. He aquí un ejemplo:
% finger johnc@idsoftware.com |
finger puede devolver nombre de usuario, estado del correo, números telefónicos, y archivos referidos como por ejemplo los “punto plan” y “punto proyecto”. Por supuesto, la información que se devuelve varía de acuerdo a cada servidor finger. El que viene con Slackware devuelve por omisión la siguiente información por omisión:
-
Nombre de usuario
-
Número de habitación
-
Número telefónico de la casa
-
Número telefónico del trabajo
-
Estado de inicio de sesión
-
Estado de correo
-
Contenido del archivo .plan en el directorio home del usuario
-
Contenido del archivo .project en el directorio home del usuario
Los primeros cuatro puntos pueden ser llenados mediante el comando chfn. Este almacena estos valores en el archivo /etc/passwd. Para cambiar la información de su archivo .plan o .project, sencillamente edítelo con su editor de texto favorito. Estos archivos deben residir en su directorio home y deben llamarse .plan y .project.
Muchos usuarios utilizan finger con sus propias cuentas desde una máquina remota, para saber rápidamente si tienen correos nuevos. O, usted puede revisar los planes o proyectos actuales de determinado usuario.
Como muchos comandos, finger tiene opciones. Revise la página man para obtener mayor información sobre las opciones especiales que usted puede usar.
13.5 telnet
Alguien alguna vez dijo que telnet(1) es la mejor cosa que ha existido en materia de computadoras. La habilidad de iniciar sesiones remotas en otras computadoras, y hacer cosas era lo que separaba a los sistemas operativos Unix y al estilo Unix del resto de los sistemas operativos.
telnet le permite iniciar sesión en una computadora, como si estuviera sentado en un terminal. Una vez que se verifica su nombre de usuario y su contraseña, se le brinda un prompt en una consola. Desde ahí, es posible hacer todo lo que requiera una consola texto. Componer correo, leer noticias, mover archivos, y cosas así. Si usted está corriendo X y hace telnet a otra máquina, puede correr programas X en la computadora remota, y mostrarlos en la suya.
Para iniciar sesión en una máquina remota, use la siguiente sintaxis:
% telnet <nombre_del_host> |
Si el host responde, usted recibirá un prompt para iniciar sesión. Dele su nombre de usuario y contraseña, y eso es todo. Ahora está en una consola. Para terminar su sesión telnet, use el comando exit o el comando logout.
 |
telnet no encripta la información que manda. Todo se manda en texto plano, incluso las contraseñas. No es recomendable utilizar telnet sobre Internet. En su lugar, considere utilizar el Secure Shell (Consola segura). Esta encripta todo el tráfico y está disponible libremente. |
13.5.1 El otro uso de telnet
Ahora que ya lo hemos convencido de no utilizar el protocolo telnet para iniciar sesión en otra máquina remota, le mostraremos un par de maneras útiles de utilizar telnet.
Ahora puede utilizar el comando telnet para conectarse a un host en determinado puerto.
% telnet <nombre_del_host> [puerto] |
Eso puede ser muy útil cuando usted necesita rápidamente probar algún servicio, y necesita control total sobre los comandos, y sobre lo que está sucediendo exactamente. Usted puede probar o utilizar interactivamente un servidor SMTP, POP3, HTTP, etc, de esta manera..
En la figura siguiente usted verá como hacer telnet a un servidor HTTP por el puerto 80, y obtener informaciones básicas sobre él.
Figura 13-1. Haciendo telnet a un servidor HTTP
% telnet store.slackware.com 80 |
13.6 La Consola Segura
Hoy, las consolas seguras disfrutan de la adoración que telnet una vez disfrutó. ssh(1) permite hacer una conexión a una máquina remota y ejecutar programas como si uno estuviera físicamente presente. Además, ssh encripta todos los datos que viajan entre dos computadoras, de manera que si alguien intercepta la conversación, no puede entenderla. Una conexión a una consola segura puede ser como la siguiente:
% ssh carrier.lizella.net -l alan |
Aquí me pueden ver haciendo una conexión ssh a carrier.lizella.net, y chequeando los permisos del archivo MANIFEST.
13.7 Correo Electrónico
El correo electrónico es una de las cosas más populares que uno puede hacer en Internet. En 1998, fue reportado que se mandaba más correo electrónico que correo postal. Este servicio es además común y útil.
En Slackware, nosotros brindamos un servidor de correo estándar, y varios clientes de correo. Todos los clientes que se discuten a continuación son basados en texto. Muchos usuarios de Windows deben estar contra esto, pero usted verá que los clientes de correo texto son especialmente convenientes, sobre todo para revisar el correo remotamente. No tema, existen muchos clientes gráficos de correo electrónico como el Kmail de KDE. Si usted desea utilizar uno de esos, revise su menú de ayuda.
13.7.1 pine
Un pino (pine(1)) no es un olmo (elm). Al menos eso dice el dicho. La Universidad de Washington creó su programa para noticias de Internet y correo electrónico dada la necesidad de un lector de correos fácil de usar para sus estudiantes. pine es uno de los clientes de correo más populares, y está disponible para casi todos los sabores de Unix e incluso para Windows.

13.7.2 elm
elm(1) es otro cliente de correo modo texto muy popular. Aunque no es tan amigable al usuario como pine, lleva mucho más tiempo en el mundo de Unix.

13.7.3 mutt
“Todos los clientes de correo apestan. Este sencillamente apesta menos.” La interfaz original de mutt fue basada en elm con algunas características traídas de otros clientes de correo populares, resultando en un mutt (mestizo) híbrido.
Algunas de las características distintivas que mutt incluye son:
-
soporta colores
-
soporta hilos de correo
-
soporta MIME y PGP/MIME
-
soporta pop3 e imap
-
soporta múltiples formatos para cuentas de correo (mbox, MMDF, MH, maildir)
-
altamente personalizable

13.7.4 nail
nail(1) es un cliente de correo controlado por la línea de comandos. Es muy primitivo, y no ofrece casi nada en materia de interfaces de usuario. De cualquier manera, mailx es útil cuando usted necesita mandar algo por correo rápidamente, probar la instalación de su MTA o algo similar. Note que Slackware crea enlaces simbólicos hacia nail desde /usr/bin/mail y /usr/bin/mailx. Cualquiera de estos tres comandos ejecutan el mismo programa. De hecho, usted verá que a nail se le llama mail.
La línea de comandos básica es:
% mailx <asunto> <dirección-a> |
mailx lee el cuerpo del mensaje desde la entrada estándar. Así que usted puede hacer cat a un archivo y ponerlo en este comando, o puede teclear texto y teclear Ctrl+D cuando termine con el mensaje.
He aquí un ejemplo de mandar las fuentes de un programa por correo a otra persona.
% cat randomfunc.c | mail -s "Here's that function" asdf@example.net |
La página man explica más de lo que puede hacer nail, así que probablemente usted desee verla antes de utilizarlo.
13.8 Navegadores
Lo primero que las personas piensan cuando escuchan la palabra Internet es “navegar por la red”. O ver sitios web mediante un navegador web. Este es probablemente por mucho el uso más popular de Internet para el usuario promedio.
Slackware brinda navegadores gráficos populares en las series “XAP”, así como navegadores modo texto en la serie “N”. Veremos rápidamente algunas de las opciones más comunes.
13.8.1 lynx
lynx(1) es un navegador modo texto. Es una manera muy rápida de buscar algo en Internet. Algunas veces los gráficos solamente se ajustan si usted conoce exactamente lo que necesita.
Para iniciar lynx, teclee lynx en el prompt
% lynx |

Usted puede especificar un sitio para que lynx lo abra:
% lynx http://www.slackware.com |
13.8.2 links
Exactamente como lynx, links es un navegador modo texto, donde usted puede hacer toda la navegación mediante el teclado. Si usted presiona la tecla Esc, esta activará un menú muy conveniente en la parte superior de la pantalla. Esto lo hace muy fácil de usar, sin tener que memorizar todos los comandos del teclado. Las personas que no usan un navegador modo texto todos los días agradecen esta funcionalidad.
links parece tener mejor soporte para marcos y tablas cuando se compara con lynx.

13.8.3 wget
wget(1) es una utilidad de línea de comandos que descarga archivos de una URL especificada. Aunque no es realmente un navegador modo texto, wget es utilizado para grabar total o parcialmente sitios web para verlos sin conexión, o para descargar rápidamente archivos individuales desde servidores HTTP o FTP. La sintaxis básica es:
% wget <url> |
Usted puede también pasarle opciones. Por ejemplo, esto descargará el sitio web de Slackware:
% wget --recursive http://www.slackware.com |
wget creará un directorio www.slackware.com y pondrá los archivos ahí, tal como lo hace el sitio.
wget también puede descargar archivos desde sitios FTP; solamente especifique una URL FTP en vez de una HTTP.
% wget ftp://ftp.gnu.org/gnu/wget/wget-1.8.2.tar.gz |
wget tiene muchas más opciones, las cuales lo hacen bueno para scripts específicos, para determinados sitios (espejos de sitios, y cosas así). La página man debe ser consultada para obtener más información.
13.9 Clientes FTP
FTP significa File Transfer Protocol (Protocolo de Transferencia de Archivos). Este permite mandar y recibir archivos entre dos computadoras. Existe el cliente FTP y el servidor FTP. En esta sección discutiremos el cliente.
Para los curiosos, el “cliente” es usted. El “servidor” es la computadora que responde sus solicitudes FTP, y le permite iniciar sesiones. Usted descargará archivos del servidor, y subirá archivos al servidor. El cliente no puede aceptar conexiones FTP, solamente puede conectarse a servidores.
13.9.1 ftp
Para conectarse a un servidor FTP, simplemente corra el comando ftp(1) y especifique el host:
% ftp <nombre_del_host> [puerto]
|
Si el host está corriendo un servidor FTP, este le preguntará su nombre de usuario y contraseña. Usted puede iniciar sesión como usted mismo, o como “anonymous” (anónimo). Los sitios FTP anónimos son muy populares para archivos de software. Por ejemplo, para obtener Slackware via FTP, usted debe usar FTP anónimo.
Una vez conectado, usted llegará al promt ftp>. Existen comandos especiales para FTP, pero son similares a otros comandos estándares. La siguiente tabla muestra algunos de los comandos básicos y la función de cada cual:
| Comando | Propósito |
|---|---|
| ls | Lista los archivos |
| cd <nombre_directorio> | Cambia de directorio |
| bin | Activa modo de transferencia binario |
| ascii | Activa modo de transferencia ASCII |
| get <nombre_archivo> | Descarga un archivo |
| put <nombre_archivo> | Sube un archivo |
| hash | Activa/Desactiva el indicador # para cada bloque de datos transferido |
| tick | Activa/Desactiva el indicador contador de bytes |
| prom | Activa/Desactiva el modo interactivo para las descargas |
| mget <máscara> | Descarga un archivo o grupo de archivos; se permiten comodines |
| mput <máscara> | Sube un archivo o grupo de archivos; se permiten comodines |
| quit | Cierra sesión en el servidor FTP |
ftp> ls *.TXT |
13.9.2 ncftp
ncftp(1) (se pronuncia "Nik-F-T-P") es una alternativa al cliente ftp tradicional que viene con Slackware. Es aún un programa en basado en texto, pero ofrece muchas ventajas sobre ftp, incluyendo:
-
Completamiento con Tab
-
Archivo de marcadores
-
Uso más liberal de comodines
-
Historial de comandos
Por omisión, ncftp intentará iniciar sesión anónima en el servidor que usted especifique. Usted puede forzar a ncftp para que inicie sesión con otro usuario con la opción “-u”. Una vez iniciada la sesión, usted puede usar los mismos comandos que usa en ftp, solo que usted verá una mejor interfaz, una que funciona como bash.
ncftp /pub/linux/slackware > cd slackware-current/ |
13.10 Hablando con Otras Personas
13.10.1 wall
wall(1) es una manera rápida de escribirle un mensaje a los usuarios del sistema. La sintaxis básica es:
% wall [archivo]
|
El resultado de este comando es que el contenido de [archivo] será mostrado en los terminales de todos los usuarios que tengan sesiones iniciadas. Si usted no especifica un archivo, wall leerá de la entrada estándar, usted puede teclear su mensaje, y terminar con Ctrl+d.
wall no tiene muchas funcionalidades, aparte de hacerle saber a los usuarios de su sistema que usted está a punto de hacer un mantenimiento serio de su sistema, e incluso reiniciarlo, para que ellos tengan tiempo de salvar su trabajo y cerrar sesión :)
13.10.2 talk
talk(1) le permite a dos usuarios charlar. Este divide la pantalla a la mitad, horizontalmente. Para solicitar charlar con otro usuario, utilice este comando
% talk <persona> [nombre_del_tty]
|

talk es un poco limitado. Solamente soporta dos usuarios y la comunicación es medio-duplex.
13.10.3 ytalk
ytalk(1) es un reemplazo compatible con talk. Viene con Slackware como el comando ytalk. La sintaxis es similar, pero tiene unas pocas diferencias:
% ytalk <nombre_de_usuario>[#nombre_del_tty]
|

Capítulo 14 Seguridad
14.1 Deshabilitando Servicios
El primer paso después de instalar Slackware debe ser deshabilitar todos los servicios que usted no necesite. Cualquier servicio puede, potencialmente, ser un riesgo de seguridad; por ende es importante correr tan pocos servicios como sea posible (dígase, solamente los necesarios). Los servicios se inician desde dos lugares principales: inetd y los scripts init.
14.1.1 Servicios que arrancan desde inetd
Muchos de los demonios que vienen con Slackware corren desde inetd(8). inetd es un demonio que escucha en todos los puertos que utilizan los servicios que tenga configurado para que inicien mediante él, y levanta una instancia del demonio en cuestión cuando se realiza un intento de conexión. Los demonios que inician desde inetd pueden ser deshabilitados comentando las líneas relevantes en /etc/inetd.conf. Para hacer esto, abra este archivo en su editor favorito (por ejemplo, vi), donde debe ver líneas similares a esta:
telnet stream tcp nowait root /usr/sbin/tcpd in.telnetd |
Usted puede deshabilitar este servicio, y todos los demás que no necesite, comentándolos (dígase, adicionando un símbolo de número # al inicio de la línea). La línea anterior entonces se convertiría en:
#telnet stream tcp nowait root /usr/sbin/tcpd in.telnetd |
Después que inetd se haya reiniciado, este servicio será deshabilitado. Usted puede reiniciar inetd con el comando:
# kill -HUP $(cat /var/run/inetd.pid)
|
14.1.2 Servicios que arrancan desde los scripts init
El resto de los servicios que arrancan cuando la máquina arranca se inician desde los scripts init, en /etc/rc.d/. Estos pueden ser deshabilitados de dos maneras diferentes, la primera es quitándole los permisos de ejecución a aquellos scripts relevantes, y la segunda manera es comentar las líneas relevantes dentro de los scripts init.
Por ejemplo, SSH arranca mediante su propio script en /etc/rc.d/rc.sshd. Usted puede deshabilitarlo usando:
# chmod -x /etc/rc.d/rc.sshd
|
Para aquellos servicios que no tienen su propio script init, usted necesitará comentar las líneas relevantes en los scripts init para deshabilitarlos. Por ejemplo, el demonio portmap arranca desde las líneas siguientes de /etc/rc.d/rc.inet2:
# This must be running in order to mount NFS volumes. |
Este puede ser deshabilitado adicionando símbolos # al inicio de aquellas líneas que no comiencen con él, como sigue:
# This must be running in order to mount NFS volumes. |
Estos cambios solamente tendrán efecto después de reiniciar o después de un cambio de runlevel 3 o 4. Usted puede hacer esto tecleando lo siguiente en una consola (usted necesitará iniciar sesión después de cambiar a runlevel 1):
# telinit 1 |
14.2 Control de Acceso al Host
14.2.1 iptables
iptables es el programa de configuración de filtrado de paquetes desde Linux 2.4 en adelante. El núcleo 2.4 (2.4.5, para ser exactos) fue el primero que introdujo en Slackware (como opción) en la versión 8.0 y fue hecho por omisión en Slackware 8.1. Esta sección solamente cubre lo básico de su uso, y usted debe revisar http://www.netfilter.org/ para obtener más detalles. Estos comandos pueden ser entrados desde /etc/rc.d/rc.firewall, el cual tiene que ser hecho ejecutable para que estas reglas tengan efecto al inicio. Note que los comandos iptables pueden básicamente bloquear su propia máquina. A menos que usted está 100% seguro de sus habilidades, siempre asegúrese de tener acceso local a la máquina.
La primera cosa que la mayoría de las personas deben hacer es que cada cadena que llegue de fuera se deseche (DROP) por omisión:
# iptables -P INPUT DROP |
Cuando todo esté denegado, usted puede comenzar a permitir cosas. La primera cosa que usted debe permitir es el tráfico de las sesiones que ya estén establecidas:
# iptables -A INPUT -m state --state ESTABLISHED,RELATED -j ACCEPT
|
Para no bloquear aplicaciones que se comunican utilizando la dirección de loopback, normalmente es inteligente adicionar reglas como esta:
# iptables -A INPUT -s 127.0.0.0/8 -d 127.0.0.0/8 -i lo -j ACCEPT
|
Esta regla permite que cualquier tráfico que venga y vaya hacia 127.0.0.0/8 (127.0.0.0 - 127.255.255.255) la interfaz de loopback (lo). Cuando se crean reglas, es una buena idea ser tan específico como sea posible, pues así se asegura de que sus reglas no permiten pasar nada malo. Dicho esto, las reglas que permiten muy poco significan más reglas, y más tecleo.
La próxima coas que usted debe hacer es permitir acceso a los servicios específicos que corren en su máquina. Si, por ejemplo, usted desea correr un servidor web en su máquina, usted debe tener una regla similar a esta:
# iptables -A INPUT -p tcp --dport 80 -i ppp0 -j ACCEPT
|
Esto permitirá acceso desde cualquier máquina al puerto 80 desde la interfaz ppp0. Usted puede desear restringir el acceso a este servicio para que solamente determinadas máquinas puedan acceder a este. Esta regla habilita su servicio web solamente a 64.57.102.34:
# iptables -A INPUT -p tcp -s 64.57.102.34 --dport 80 -i ppp0 -j ACCEPT
|
Permitir tráfico ICMP puede ser útil para propósitos de diagnóstico. Para hacer esto, usted debe usar una regla como esta:
# iptables -A INPUT -p icmp -j ACCEPT
|
La mayoría de las personas también desearán configurar Network Address Translation (Traducción de Direcciones de Red, NAT) en su máquina pasarela, de manera que otras máquinas de su red puedan acceder a Internet mediante esta. Usted puede utilizar la siguiente regla para hacer esto:
# iptables -t nat -A POSTROUTING -o ppp0 -j MASQUERADE
|
Usted también necesitará habilitar IP forwarding. Usted puede hacer esto temporalmente utilizando el siguiente comando:
# echo 1 > /proc/sys/net/ipv4/ip_forward
|
Para habilitar IP forwarding de manera más permanente (por ejemplo para que los cambios se mantengan después de reiniciar), usted necesitará abrir el archivo /etc/rc.d/rc.inet2 en su editor de texto favorito y cambiar la siguiente línea:
IPV4_FORWARD=0 |
...a esto:
IPV4_FORWARD=1 |
Para obtener más información sobre NAT, vea el NAT HOWTO.
14.2.2 tcpwrappers
tcpwrappers controla el acceso a los demonios a nivel de aplicación, en vez de a nivel de IP. Esto brinda una capa extra de seguridad, cuando el control a nivel de IP (por ejemplo Netfilter) no está funcionando correctamente. Por ejemplo, si usted recompila el núcleo y olvida poner el soporte a iptables, su protección a nivel de IP fallará, pero tcpwrappers aún puede ayudar a proteger su sistema.
El acceso a los servicios protegidos por tcpwrappers puede ser controlado desde /etc/hosts.allow y /etc/hosts.deny.
La mayoría de las personas deben tener una sola línea en su archivo /etc/hosts.deny para denegar el acceso a todos los demonios por omisión. Esta línea debe ser:
ALL : ALL |
Cuando se hace esto, usted puede concentrarse en permitir el acceso a los servicios especificados para determinados host, dominios, o rangos IP. Esto puede ser hecho en el archivo /etc/hosts.allow, el cual sigue el mismo formato.
Muchas personas comenzarían aceptando todas las conexiones desde localhost. Esto puede realizarse utilizando:
ALL : 127.0.0.1 |
Para pemitir acceso a SSHd desde 192.168.0.0/24, usted puede usar cualquiera de las siguientes reglas:
sshd : 192.168.0.0/24 |
También es posible restringir el acceso a hosts en determinados dominios. Esto puede hacerse con la siguiente regla (nótese que descansa en una entrada de DNS inverso para que el host que se conecta sea confiable, de manera que no recomiendo su uso en hosts conectados a Internet):
sshd : .slackware.com |
14.3 Manteniéndose Actualizado
14.3.1 La lista de correo slackware-security
Siempre que un problema de seguridad afecte Slackware, se le manda un correo a todos los subscriptores de la lista de correos slackware-security@slackware.com. Los reportes se mandan para las vulnerabilidades de cualquier parte de Slackware, aparte del software que se encuentra en /extra o en /pasture. Estos correos con anuncios de seguridad incluyen detalles de como obtener las versiones actualizadas de los paquetes Slackware, o las vías para resolver el problema, si existen.
Cómo suscribirse a la lista de Slackware se cubre en la Sección 2.2.2.
14.3.2 El directorio /patches
Siempre que un paquete actualizado sea liberado para cualquier versión de Slackware (usualmente solo para resolver problemas de seguridad, en el caso de las versiones de Slackware ya liberadas) este se pone en el directorio /patches. El camino completo a esos parches dependerá del espejo que usted esté usando, pero normalmente toman la forma de /camino/a/slackware-x.x/patches/.
Antes de instalar estos paquetes, es una buena idea verificar la suma md5sum del paquete. md5sum(1) es una utilidad de línea de comandos que crea una secuencia matemática “única” del archivo. Si solamente un bit de ese archivo ha cambiado, este generará un valor diferente al aplicarle md5sum.
% md5sum paquete-<ver>-<arquitectura>-<rev>.tgz |
Usted debe chequear esto contra la línea del nuevo paquete que se encuentra en el archivo CHECKSUMS.md5 en la raíz del directorio slackware-$VERSION (también en el directorio /patches para los parches) o en el correo electrónico de la lista slackware-security.
Si usted tiene un archivo con los valores md5sum, usted puede utilizarlo como fuente con la opción -c de md5sum.
# md5sum -c CHECKSUMS.md5 |
Como puede observar, todos los archivos que md5sum evaluó como correctos está marcados como “OK” mientras que los incorrectos están marcados como “FAILED”. (Sí, esto fue un insulto a su inteligencia).
Capítulo 15 Compactando Archivos
15.1 gzip
gzip(1) es el programa de compresión de GNU. Este toma un solo archivo y lo comprime. El uso básico es el siguiente:
% gzip nombredearchivo
|
El archivo resultante se llamará nombredearchivo.gz y normalmente será menor que el archivo de entrada. Nótese que nombredearchivo.gz reemplazará a nombredearchivo. Esto significa que nombredearchivo no existirá más, sino su copia gzipeada. Los archivos de texto regular se comprimen bien, mientras que las imágenes jpeg, mp3s, y otros archivos de esa índole no comprimen muy bien, pues ya están comprimidos de antemano. El uso básico es un balance entre el tiempo de compresión y tamaño del archivo. La compresión máxima puede ser lograda así:
% gzip -9 nombredearchivo
|
Esto tomará más tiempo para comprimir el archivo, pero el resultado será un archivo tan pequeño como pueda gzip. Usar valores más bajos para la opción de línea de comandos causará que comprima más rápido, pero no comprimirá demasiado.
Para descomprimir archivos gzipeados pueden usarse dos comandos, los cuales son en realidad el mismo programa. gzip descomprimirá cualquier archivo que tenga una extensión reconocible por él, o sea, cualquiera de las siguientes: .gz, -gz, .z, -z, .Z, o -Z. El primer método es llamar gunzip(1) para un archivo, así:
% gunzip nombredearchivo.gz
|
Esto dejará la versión descomprimida del archivo de entrada en el directorio actual, y la extensión .gz será retirada del nombre de archivo. gunzip es realmente parte de gzip y es idéntico a gzip -d. Por ende, muchas veces gzip se pronuncia como gunzip, puesto que este segundo nombre suena mucho mejor. :^)
15.2 bzip2
bzip2(1) es un programa alternativo de compresión instalado en Slackware Linux. Este usa un algoritmo de compresión diferente de gzip, lo cual tiene ventajas y desventajas. La principal ventaja de bzip2 es el tamaño del archivo comprimido. bzip2 casi siempre comprimirá mejor que gzip. En algunos casos, el resultado puede ser archivos mucho más pequeños. Esto puede ser una gran ventaja para aquellas personas que tienen una conexión lenta a través de un modem. También recuerde, que cuando usted descarga software desde un servidor público ftp, generalmente es una buena netiquette descargar los archivos .bz2 en vez de los .gz, pues esto resulta en menos tara para aquellos que generosamente están alojando el servidor.
La desventaja de bzip2 es que es más intensivo a la CPU que gzip. Esto significa que utilizar bzip normalmente tomará más tiempo que utilizar gzip. Cuando se considera que programa de compresión utilizar, usted debe balancear velocidad vs. tamaño de la copia comprimida y determinar qué es más importante.
El uso de bzip2 es casi idéntico al de gzip, así que no pasaremos mucho tiempo discutiéndolo. Como gunzip, bunzip2 es idéntico a bzip2 -d. La diferencia primaria en la práctica es que bzip2 usa la extensión .bz2.
% bzip2 nombredearchivo |
15.3 tar
tar(1) es el archivador en cinta GNU. Este toma muchos archivos o directorios y crea un archivo grande. Esto permite comprimir un árbol de directorios completo, lo cual es imposible solamente usando gzip o bzip2. tar tiene muchas opciones en la línea de comandos, las cuales se explican en su página man. Esta sección solamente cubre los usos más comunes de tar.
El uso más común de tar es descomprimir y desarchivar un paquete que usted ha descargado de un sitio web o ftp. La mayoría de los archivos vienen con una extensión .tar.gz. Esto es comúnmente conocido como un “tarball”. Esto significa que varios archivos fueron archivados usando tar y luego comprimidos usando gzip. Usted puede también ver estos archivos como .tar.Z. Esto significa la misma cosa, pero normalmente se encuentra en sistemas Unix más viejos.
Alternativamente, usted puede encontrar un archivo .tar.bz2 por ahí. Las fuentes del núcleo de Linux se distribuyen de esta manera puesto que son más pequeñas para descargarlas. Como usted habrá supuesto, estos son muchos archivos agrupados con tar y luego comprimidos con bzip2
Usted puede obtener todos los archivos que se encuentran en este archivo haciendo uso de tar y algunos argumentos. Desarchivar un tarball hace uso de la bandera -z, la cual significa que primero pase el archivo por gunzip y lo descomprima. La manera más común de hacer esto es como sigue:
% tar -xvzf nombredearchivo.tar.gz
|
Realmente son pocas opciones. ¿Entonces, qué significan? El -x significa que extraiga. Esto es importante, ya que le dice a tar exactamente que hacer con el archivo de entrada. En este caso, estaremos dividiendo el archivo en sus componentes originales. -v significa que sea muy comunicativo. Esto mostrará todos los archivos que están siendo desarchivados. Es perfectamente aceptable no poner esta opción, pues es un poco aburrida. Alternativamente, usted puede usar la opción -vv para que sea muy muy comunicativo, y ponga aún más información sobre los archivos que se extraen. La opción -z le dice a tar que corra nombredearchivo.tar.gz primero a través de gunzip. Y finalmente, la opción -f le dice a tar que la próxima cadena de la línea de comando es el archivo sobre el cual debe operar.
Existen otras maneras de escribir el mismo comando. En sistemas más antiguos, que carecen de una copia decente del tar de GNU, usted puede ver esto escrito como:
% gunzip nombredearchivo.tar.gz | tar -xvf -
|
Este comando descomprimirá el archivo y mandará la salida a tar. Como gzip escribirá su salida en la salida estándar si se le ordena, este comando escribirá el archivo descomprimido en la salida estándar. La tubería se lo manda a tar para que lo desarchive. El “-” significa que opere con la entrada estándar. Esto desarchivará el flujo de datos que le llega de gzip y lo escribirá en el disco.
Otra manera de escribir la primera línea de comandos es eliminando el guión que precede a las opciones, así:
% tar xvzf nombredearchivo.tar.gz
|
Usted también puede encontrarse un archivo comprimido con bzip. La versión de tar que viene con Slackware Linux es capaz de manejar este tipo de archivos, del mismo modo que los comprimidos con gzip. En lugar de la opción -z en la línea de comandos, usted debe utilizar -j:
% tar -xvjf nombredearchivo.tar.bz2
|
Es importante notar que tar va a poner los archivos extraidos en el directorio actual. Así que si usted tiene un archivo en /tmp que desea extraer en su directorio home, realmente tiene pocas opciones. La primera: el archivo puede ser movido hacia su directorio home y luego correr tar. La segunda, usted puede especificar el camino al archivo en la línea de comandos. La tercera, usted puede usar la opción -C para “explotar” el tarball en un directorio especificado.
% cd $HOME |
Todas las sentencias anteriores son equivalentes. En cada caso, el archivo es extraído dentro de su directorio home, y el archivo comprimido original es dejado en su lugar.
¿Y qué puede tener de bueno descomprimir archivos si no puede comprimirlos? Bueno, tar también hace eso. En la mayoría de los casos es tan sencillo como eliminar la opción “-x” y reemplazarla con la opción “-c”.
% tar -cvzf nombredearchivo.tar.gz .
|
En esta línea de comandos, la opción -c le dice a tar que cree un archivo, mientras que la opción -z corre el archivo resultante a través de gzip para comprimirlo. nombredearchivo.tar.gz es el archivo que usted desea crear.
Especificar la opción “-f” no siempre es necesario, pero típicamente es una buena práctica. Si esta, tar escribe en la salida estándar, lo cual es usualmente lo deseado para conducir la salida de tar hacia otro programa, como sigue:
% tar -cv nombredearchivo.tar . | gpg --encrypt
|
Este comando crea un archivo tar no comprimido del directorio actual, y conduce el tarball hacia gpg el cual encripta y comprime el tarball, siendo realmente imposible que sea leído por otra persona que no conozca la clave secreta.
15.4 zip
Finalmente, existen dos utilidades que pueden ser usadas en archivos zip. Los archivos zip son muy comunes en el mundo de Windows, así que Linux tiene programas para tratar con ellos. El programa de compresión se llama zip(1),y el de descompresión se llama unzip(1).
% zip foo *
|
Esto creará el archivo foo.zip, el cual contendrá todos los archivos del directorio actual. zip adicionará la extensión .zip automáticamente, así que no hay necesidad de incluirla en el nombre del archivo. Usted puede también comprimir directorios de manera recursiva:
% zip -r foo *
|
Descomprimir archivos es fácil, también:
% unzip foo.zip
|
Esto extraerá todos los archivos en el archivo foo.zip, incluyendo cualquier directorio en el archivo.
Las utilidades zip tienen muchas opciones avanzadas para crear archivos autoextraíbles, dejar ciertos archivos fuera, controlar el tamaño del archivo comprimido, imprimir lo que está sucediendo, y mucho más. Vea las páginas man de zip y unzip para conocer como se utilizan estas opciones.
Capítulo 16 Vi
16.1 Iniciando vi
vi puede ser iniciado desde la línea de comandos de varias maneras. La más simple es:
% vi
|

Esto iniciará vi con un buffer vacío. En este punto, usted debe ver una pantalla en blanco. Se encuentra ahora en “modo comando”, esperando que usted haga algo. Para ver una discusión sobre los diferentes modos de vi, consulte la Sección 16.2. Para salir de vi, teclee lo siguiente:
:q
|
Asumiendo que no haya habido cambios en el archivo, esta secuencia hace que vi salga. Si se han realizado cambios, le mostrará una precaución, y le dirá como ignorarlos. Ignorarlos usualmente se resume a colocar un signo de admiración después de la “q”, como sigue:
:q!
|
El signo de exclamación usualmente significa forzar determinada acción. Discutiremos esta y otras combinaciones de teclas más adelante.
Usted puede también iniciar vi con un archivo ya existente. Por ejemplo, el archivo /etc/resolv.conf puede ser abierto de la siguiente manera:
% vi /etc/resolv.conf
|
Finalmente, vi puede ser iniciado en una línea particular de un archivo. Esto es especialmente útil para los programadores, cuando un mensaje de error especifica la línea donde el programa explota. Por ejemplo, usted puede iniciar vi en la línea 47 de /usr/src/linux/init/main.c así:
% vi +47 /usr/src/linux/init/main.c
|
vi mostrará el archivo dado y colocará el cursor en la línea especificada. En caso de especificarse una línea que se encuentre más allá del final del archivo, vi colocará el cursor en la última línea.
16.2 Modos
vi opera en varios modos, los cuales se utilizan para acometer diversas tareas. Cuando usted inicia vi, usted se encuentra en modo comando. A partir de ese punto, usted puede invocar varios comandos para manipular texto, moverse por el archivo, salvar, salir y cambiar modos. La edición del texto se realiza en modo insertar. Usted puede moverse rápidamente entre los diferentes modos con varias combinaciones de teclas, las cuales se explican a continuación.
16.2.1 Modo Comando
Usted inicialmente se encuentra en modo comando. A partir de ese modo, usted no puede entrar texto directamente o editar el existente. En cambio, puede manipular texto, buscar, salir, salvar, cargar nuevos archivos y más. Esto solamente es una introducción al modo comando. Para obtener una descripción de los diferentes comandos, vea la Sección 16.7.
Probablemente el comando más utilizado en modo comando sea el de cambiarse a modo insertar. Esto se realiza oprimiendo la tecla i. La forma del cursor cambia, y se muestra -- INSERT -- en la parte baja de la pantalla (note que esto no sucede en todos los clones de vi). Desde ahí, todas las combinaciones de teclas son almacenadas en el buffer actual y son mostradas en la pantalla. Para regresar al modo comando, presione la tecla ESCAPE.
El modo comando se utiliza también para moverse por el archivo. En algunos sistemas, usted puede usar las teclas con las flechas para moverse por el archivo. En otros sistemas, puede que necesite utilizar las teclas tradicionales “hjkl”. He aquí una lista de como utilizar estas teclas para moverse:
16.2.2 Modo Insertar
El insertado y reemplazo de texto se realizan en modo inserción. Como hemos discutido previamente, usted puede ir al modo insertar presionando la tecla i desde el modo comando. A partir de ese momento, todo el texto que usted entre irá a parar al buffer actual. Para retornar al modo comando, presione la tecla ESCAPE.
El reemplazo de texto puede realizarse de diversas maneras. En modo comando, presionando la tecla r se reemplaza el caracter bajo el cursor. Sencillamente teclee un nuevo caracter y reemplazará al que se encuentra bajo el cursor. Inmediatamente después, retornará al modo comando. Presionando R usted puede reemplazar tantos caracteres como desee. Para salir de este modo de reemplazo, y regresar al modo comando, presione ESCAPE.
Existe aún otra manera de intercambiar entre el modo insertar y el modo reemplazo. Presionando la tecla INSERT desde el modo comando, lo pondrá en modo insertar. Una vez en modo insertar, la tecla INSERT del teclado sirve para intercambiar entre inserción y reemplazo. Presiónela una vez más para pasar de nuevo al modo inserción.
16.3 Abriendo Archivos
vi le permite abrir archivos desde el modo comando, aunque también puede especificarlo directamente desde la línea de comandos. Para abrir el archivo /etc/lilo.conf:
:e /etc/lilo.conf
|
Si usted ha hecho cambios en el buffer actual sin salvar, vi se quejará. Usted puede abrir el archivo de todas maneras, tecleando :e!, seguido de un espacio y el nombre del archivo. En general, las precauciones de vi pueden ser eliminadas siguiendo el comando de un signo de exclamación.
Si usted desea reabrir el archivo actual, usted puede hacerlo tecleando simplemente e!. Esto es particularmente útil si usted se ha perdido de alguna manera en el archivo y desea reabrirlo.
Algunos clones de vi (por ejemplo, vim) permiten múltiples buffers abiertos al mismo tiempo. Por ejemplo, para abrir el archivo 09-vi.sgml en mi directorio home mientras otro archivo está abierto, debo teclear:
:split ~/09-vi.sgml
|
El nuevo archivo es mostrado en la mitad superior de la pantalla, y el viejo en la mitad inferior de la pantalla. Existen múltiples comandos que manipulan la pantalla dividida, y muchos de estos comienzan a parecerse en algo a Emacs. El mejor lugar para obtener ayuda sobre esos comandos, es la página man del clon de vi en particular. Note que muchos clones no soportan la idea de la pantalla dividida, así que es probable que usted no pueda hacer uso de esta potencialidad.
16.4 Salvando Archivos
Existen muchas maneras de salvar archivos en vi. Si usted desea salvar el buffer actual en un archivo llamado randomness, usted debe teclear:
:w randomness
|
Una vez que usted haya salvado el archivo, para salvarlo otra vez simplemente debe teclear :w. Cualquier cambio realizado será escrito hacia el archivo. Una vez que usted haya salvado el archivo, será catapultado de regreso al modo comando. Si usted desea salvar el archivo y salir de vi (una operación muy común), usted debe teclear :wq.
En ocasiones, usted desea salvar un archivo que está marcado como solo lectura. Usted puede hacer esto adicionando un signo de exclamación al final del comando escribir, así:
:w!
|
Incluso con este comando, hay ocasiones en las cuales usted no podrá escribir el archivo (por ejemplo, si usted está intentando editar un archivo que le pertenece a otro usuario). Cuando esto sucede, vi le informará que no puede salvar el archivo. Si aún desea editar el archivo en cuestión, tendrá que regresar y editar el archivo como root o (preferentemente) como el dueño de ese archivo.
16.5 Saliendo de vi
Una manera de salir de vi es a través de :wq, el cual salvará el buffer actual antes de salir. Usted puede también salir sin salvar con :q o (más comúnmente) :q!. El último es utilizado cuando usted ha realizado modificaciones en el archivo pero no desea salvarlas.
En ocasiones, su máquina puede caerse o vi puede caerse. En cualquiera de estos casos, tanto elvis como vim tomarán medidas para minimizar el daño a cualquier buffer abierto. Ambos editores salvan los buffers abiertos hacia un archivo temporal. Este archivo usualmente tiene el mismo nombre del archivo abierto, pero con un punto en el comienzo. Esto hace que este archivo sea oculto.
Este archivo temporal es eliminado una vez que el editor sale bajo condiciones normales. Esto significa que la copia temporal se quedará por los alrededores si algo falla. Cuando usted regrese a editar el archivo, se le preguntará que acción realizar. En la mayoría de los casos, una gran parte del trabajo puede ser recuperado. elvis además le enviará un correo (de Graceland, cosa rara :) diciéndole que existe una copia de respaldo.
16.6 Configuración de vi
El clon de vi de su preferencia puede ser configurado de muchas maneras.
Una variedad de comandos pueden ser entrados desde el modo comando para configurar vi exactamente a su gusto. En dependencia de su editor, usted puede activar características que faciliten la programación (como resaltado de sintaxis, sangrías automáticas, y más), configuración de macros que automaticen tareas, habilitar sustituciones textuales y más.
Casi todos estos comandos pueden ser puestos en un archivo de configuración en su directorio home. elvis espera un archivo .exrc, mientras que vim espera un archivo .vimrc. La mayoría de los comandos que se introducen en modo comando pueden ponerse en el archivo de configuración. Esto incluye información de configuración, sustituciones textuales, macros y más.
Discutir todas esas opciones y las diferencias entre los editores es realmente un asunto complicado. Para más información al respecto, revise la página man de su editor vi favorito. Algunos editores (como vim) tienen abundante ayuda dentro del editor que puede ser alcanzada mediante el comando :help, o alguno similar. Usted puede revisar además el libro de O'Reilly llamado Learning the vi Editor, por Lamb y Robbins.
Muchos programas comunes en Linux cargarán un archivo texto en vi por omisión. Por ejemplo, para editar las tablas del cron, se cargará vi por omisión. Si a usted no le agrada vi y desea utilizar algún otro editor en su lugar, todo lo que necesita hacer es poner en la variable de entorno VISUAL el editor que prefiera. Para obtener información de como trabajar con variables de entorno, vea la sección llamada Variables de Entorno en el Capítulo 8. Si usted desea asegurarse de que su editor será el de su preferencia cada vez que inicie sesión, adicione la configuración de VISUAL a su archivo .bash_profile o .bashrc.
16.7 Teclas en vi
Esta sección es una referencia rápida a los comandos más comunes de vi. Algunos de estos comandos fueron discutidos antes en este capítulo, y muchos puede que sean nuevos.
| Operación | Tecla |
|---|---|
| izquierda, abajo, arriba, derecha | h, j, k, l |
| Al final de la línea | $ |
| Al principio de la línea | ^ |
| Al final del archivo | G |
| Al principio del archivo | :1 |
| A la línea 47 | :47 |
| Operación | Tecla |
|---|---|
| Eliminar una línea | dd |
| Eliminar cinco líneas | 5dd |
| Reemplazar un caracter | r |
| Eliminar un caracter | x |
| Eliminar diez caracteres | 10x |
| Deshacer la última acción | u |
| Unir la línea actual y la siguiente | J |
| Reemplazar old por new, globalmente | %s'old'new'g |
| Operación | Tecla |
|---|---|
| Buscar “asdf” | /asdf |
| Buscar hacia atrás “asdf” | ?asdf |
| Repetir la última búsqueda hacia delante | / |
| Repetir la última búsqueda hacia atrás | ? |
| Repetir la última búsqueda, en la misma dirección | n |
| Repetir la última búsqueda, dirección opuesta | N |
| Operación | Tecla |
|---|---|
| Salir | :q |
| Salir sin salvar | :q! |
| Escribir y salir | :wq |
| Escribir sin salir | :w |
| Recargar el archivo abierto actualmente | :e! |
| Escribir el buffer hacia el archivo asdf | :w asdf |
| Abrir el archivo hejaz | :e hejaz |
| Leer el archivo asdf hacia el buffer | :r asdf |
| Leer la salida de ls hacia el buffer | :r !ls |
Capítulo 17 Emacs
17.1 Iniciando emacs
Emacs puede ser iniciado desde la consola simplemente tecleando emacs. Cuando usted esté corriendo X, Emacs (normalmente) abrirá su propia ventana X, usualmente con una barra de tareas encima, donde podrá encontrar las funciones más comunes. Al iniciar, Emacs primero mostrará un mensaje de bienvenida, y en unos pocos segundos, lo pondrá en el buffer *scratch* (Ver la Sección 17.2.)

Usted puede iniciar Emacs en un archivo existente tecleando
% emacs /etc/resolv.conf
|
17.1.1 Teclas de comando
Como se mencionó al inicio, Emacs utiliza combinaciones de Control y Alt para los comandos. La convención usual es escribirlos con la letra C y con la letra M, respectivamente. Así, C-x significa Control+x, y M-x significa Alt+x. (Se utiliza la letra M en vez de la A porque originalmente la tecla no se llamaba Alt sino Meta. La tecla Meta ha desaparecido de los teclados de computadoras, y en Emacs la tecla Alt ha tomado sus funciones.)
Muchos comandos de Emacs consisten en una secuencia de teclas y combinaciones de teclas. Por ejemplo, C-x C-c (esto es Control-x seguido de Control-c ) sale de Emacs, C-x C-s salva el archivo actual. Mantenga en mente que C-x C-b no es lo mismo que C-x b. El primero significa Control-x seguido de Control-b, mientras que el segundo significa Control-x seguido simplemente por 'b'.
17.2 Buffers
En Emacs, el concepto de “buffer” es esencial. Cada archivo que usted abra es cargado en su propio buffer. Además de estos, Emacs tiene muchos buffers especiales que no contienen archivos, sino que se utilizan para otros fines. Esos buffers especiales comienzan con asterisco. Por ejemplo, el buffer que Emacs muestra cuando es iniciado, es el conocido buffer *scratch*. En el buffer *scratch*, usted puede teclear texto de manera normal, pero el texto que se teclee ahí no será salvado cuando se cierre Emacs.
Existe otro buffer especial que usted necesita conocer, y es el minibuffer. Este buffer consiste solo de una línea, y siempre se encuentra en la pantalla: es la última línea de la ventana Emacs, debajo de la barra de estado del buffer actual. El minibuffer es donde Emacs muestra mensajes al usuario, y donde se ejecutan los comandos que necesitan entradas del usuario. Por ejemplo, cuando usted abre un archivo, Emacs preguntará el nombre de este en el minibuffer.
El intercambio entre un buffer y otro puede realizarse utilizando el comando C-x b. Este preguntará por el nombre del buffer (el nombre del buffer es usualmente el nombre del archivo que usted está editando en él), y brinda una opción por omisión, la cual es normalmente el buffer en el que usted se encontraba antes de crear el buffer actual, o antes de moverse a este. Si solamente presiona Enter, irá a parar al buffer por omisión.
Si usted desea cambiarse a otro buffer diferente del que ofrece Emacs por omisión, sencillamente teclee el nombre. Note que usted puede usar aquí el completamiento con Tab: teclee las primeras letras del nombre del buffer y presione Tab; Emacs completará el nombre del buffer. El completamiento con Tab funciona en Emacs en todos lugares donde tenga sentido.
Usted puede obtener una lista de los buffers abiertos presionando C-x C-b. Este comando usualmente dividirá la pantalla en dos, mostrando el buffer en el cual usted está trabajando en la mitad superior, y en la otra mitad un nuevo buffer llamado *Buffer List*. Este buffer contendrá una lista de todos los buffers, sus tamaños y modos, y los archivos, si existe alguno, a los cuales estos buffers estén visitando (como se le llama en Emacs). Usted puede salir de la pantalla dividida tecleando C-x 1.
|
En X, la lista de buffers está también disponible en el menú Buffer de la barra de menú. |
17.3 Modos
Cada buffer en Emacs tiene un modo asociado. Este modo representa una idea muy diferente a los modos en vi: el modo le dice a usted en qué clase de buffer se encuentra. Por ejemplo, existe un modo texto para los archivos normales de texto, pero existen otros como por ejemplo el modo c para editar programas de C, el modo sh para editar scripts de la consola, el modo latex para editar archivos LaTeX, el modo correo para editar mensajes de correo electrónico o de grupos de noticias, etc. Un modo brinda personalizaciones y funcionalidades que son útiles de acuerdo al tipo de archivo que esté editando. Es posible incluso que un modo redefina teclas y comandos. Por ejemplo, en modo texto, la tecla Tab simplemente salta hacia la próxima parada de Tab, mientras que en muchos modos de programación, la tecla Tab pone márgenes a la línea actual de acuerdo con la profundidad del bloque en el que se encuentre dicha línea.
Los modos mencionados anteriormente se denominan modos mayores. Cada buffer tiene exactamente un modo mayor. Adicionalmente, un buffer puede tener uno o más modos menores. Los modos menores brindan ciertas características adicionales que pueden ser útiles para determinadas tareas de edición. Por ejemplo, si usted presiona la tecla INSERT, usted invoca al modo sobrescribir, lo cual no es lo que usted espera. Existe también un modo autocompletar, el cual es útil en combinación con el modo texto o con el modo latex: este modo causa que cada línea termine al llegar a un determinado número de caracteres. Sin este modo autocompletar, usted necesitará presionar M-q para llenar un párrafo. (Aunque puede utilizar la función reformatear párrafo una vez que usted haya puesto algún texto en este, y ya no luzca bien organizado.)
17.3.1 Abriendo Archivos
Para abrir un archivo en Emacs, teclee
C-x C-f
|
Emacs le preguntará el nombre del archivo, poniendo un camino por omisión (que usualmente es ~/ ). Después de teclear el nombre del archivo (usted puede usar el completamiento con Tab) y presionar ENTER , Emacs abrirá el nuevo archivo en un nuevo buffer y mostrará el buffer en la pantalla.
|
Emacs creará automáticamente un nuevo buffer. El archivo no se cargará en el buffer actual. |
Para crear un nuevo archivo en Emacs, usted no puede sencillamente arrancar a teclear. Usted debe primero crear un buffer para el texto, y ponerle un nombre al archivo. Usted puede hacer esto tecleando C-x C-f y a continuación el nombre del archivo, tal y como si estuviera abriendo un archivo existente. Emacs se dará cuenta que el archivo no existe y creará un nuevo buffer, reportando “(Nuevo archivo)” en el minibuffer.
Cuando usted teclee C-x C-f y luego el nombre de un directorio en lugar del nombre de un archivo, Emacs creará un nuevo buffer en el cual usted encontrará un listado de todos los archivos en el directorio. Usted puede mover el cursor hasta el archivo que esté buscando, y teclear, y Emacs lo abrirá para usted. (Existen otras acciones que pueden ser realizadas, como eliminar, renombrar, mover archivos, etc. Emacs se encuentra en modo directorio, que es básicamente un gestor de archivos sencillo.)
Cuando usted haya tecleado C-x C-f y cambie de parecer rápidamente, puede teclear C-g para cancelar la acción. C-g funciona en casi cualquier lugar, en caso de que usted haya ejecutado un comando o acción, y no desea que sea concluida.
17.4 Edición Básica
Cuando usted tiene un fichero abierto, puede, por supuesto, moverse dentro de este con el cursor. Las teclas de cursor y PgUp, PgDn hacen lo que usted espera que hagan. Home y End saltan al principio y al final de la línea (En versiones anteriores, realmente saltaban del comienzo al final del buffer.) Además, existen las combinaciones de teclas con Control y Meta (Alt) que también mueven el cursor. Como usted no necesita mover sus manos a otra parte del teclado para esto, son mucho más veloces una vez que se acostumbre. Los comandos más importantes se listan en la Tabla 17-1.
Tabla 17-1. Comandos Básicos de Edición en Emacs
| Comando | Resultado |
|---|---|
| C-b | Retrocede un caracter |
| C-f | Avanza un caracter |
| C-n | Baja una línea |
| C-p | Sube una línea |
| C-a | Va al comienzo de la línea |
| C-e | Va al final de la línea |
| M-b | Retrocede una palabra |
| M-f | Avanza una palabra |
| M-} | Avanza un párrafo |
| M-{ | Retrocede un párrafo |
| M-a | Retrocede una oración |
| M-e | Avanza una oración |
| C-d | Elimina el caracter bajo el cursor |
| M-d | Elimina hasta el final de la palabra actual |
| C-v | Baja una pantalla (igual a PgDn) |
| M-v | Sube una pantalla (igual a PgUp) |
| M-< | Va al inicio del buffer |
| M-> | Va al final del buffer |
| C-_ | Deshace el último cambio (puede repetirse) note que usted realmente necesita teclear Shift+Control+guión. |
| C-k | Elimina hasta el final de la línea |
| C-s | Búsqueda hacia delante |
| C-r | Búsqueda hacia atrás |
17.5 Salvando Archivos
Para salvar un archivo, usted debe teclear
C-x C-s
|
Emacs no le pedirá un nombre de archivo, el buffer se salvará en el archivo desde el cual fue cargado. Si usted desea salvar el texto en otro archivo, teclee
C-x C-w
|
Cuando usted salve el archivo por primera vez en la sesión, Emacs normalmente salvará la versión anterior en un archivo de respaldo, el cual tendrá el mismo nombre con una tilde al final: así que si usted está editando el archivo “autos.txt”, Emacs creará un respaldo llamado “autos.txt~”.
Esta copia de respaldo es una copia del archivo que usted ha abierto. Mientras usted está trabajando, Emacs creará con regularidad una salva automática del trabajo que usted esté realizando, hacia un archivo nombrado con signos de número: #autos.txt#. Este respaldo es eliminado cuando usted salva el archivo con C-x C-s.
Cuando termine de editar un archivo, usted puede eliminar el buffer que lo sostiene, tecleando
C-x k
|
Emacs le preguntará qué buffer desea eliminar, con el buffer actual como parámetro por omisión. Puede seleccionarlo presionando ENTER. Si usted no ha salvado el archivo aun, Emacs le preguntará si realmente desea eliminar el buffer.
17.5.1 Saliendo de Emacs
Cuando usted haya terminado de trabajar completamente con Emacs, puede teclear
C-x C-c
|
Eso sale de Emacs. Si usted tiene archivos sin salvar, Emacs se lo dirá, y le preguntará si desea salvarlos uno a uno. Si usted responde que no a ninguno, Emacs le pedirá una confirmación final y saldrá.
Capítulo 18 Gestión de Paquetes en Slackware
18.1 Panorámica del Formato de Paquetes
Antes de aprender sobre las utilidades, usted debe hacerse familiar con el formato de paquetes de Slackware. En Slackware, un paquete es simplemente un archivo tar que ha sido comprimido con gzip. Los paquetes son construidos para que se extraigan en el directorio raíz.
He aquí un programa ficticio y su paquete de ejemplo:
./ |
El sistema de paquetes extraerá este archivo en el directorio raíz para instalarlo. Se creará una entrada en la base de datos de paquetes que contenga el contenido de este paquete para que pueda ser actualizado o eliminado posteriormente.
Nótese el subdirectorio install/. Este es un directorio especial que puede contener un script de postinstalación llamado doinst.sh. Si el sistema de paquetes encuentra este archivo, lo ejecutará después de instalar el paquete.
Otros scripts pueden estar embebidos en el paquete, pero se discuten en detalle más adelante, en la Sección 18.3.2
18.2 Herramientas de Paquetes
Existen cuatro utilidades principales para la gestión de paquetes. Estas realizan la instalación, eliminación, y actualización de los paquetes.
18.2.1 pkgtool
pkgtool(8) es un programa basado en menúes que permite la instalación y eliminación de paquetes. El menú principal se muestra en la Figura 18-1.

Usted también puede ver una lista de los paquetes instalados, como se muestra en la Figura 18-2.

18.2.2 installpkg
installpkg(8) maneja la instalación de nuevos paquetes en el sistema. La sintaxis es la siguiente:
# installpkg opción nombre_del_paquete
|
Se brindan tres opciones para installpkg, pero solamente pueden ser usadas una a la vez.
Tabla 18-1. Opciones de installpkg
| Opción | Efectos |
|---|---|
| -m | Realiza una operación makepkg en el directorio actual. |
| -warn | Muestra lo que pasaría si instalara el paquete especificado. Esto es útil para sistemas de producción, ya que usted puede ver exactamente que va a suceder antes de instalar algo. |
| -r | Instala recursivamente todos los paquetes en el directorio actual y en sus descendientes. El nombre del paquete puede contener comodines, que pueden ser usados como máscaras de búsqueda cuando se instala recursivamente. |
18.2.3 removepkg
removepkg(8) maneja la eliminación de paquetes instalados del sistema. La sintaxis es como sigue:
# removepkg opción nombre_del _paquete
|
Para removepkg se brindan cuatro opciones, pero solamente una de ellas puede ser utilizada a la vez.
Tabla 18-2. Opciones de removepkg
| Opción | Efectos |
|---|---|
| -copy | El paquete es copiado al directorio de paquetes preservados. Esto crea el árbol del paquete original sin eliminarlo. |
| -keep | Salva los archivos temporales que se crean durante la eliminación. Útil solamente para propósitos de debugging. |
| -preserve | El paquete es eliminado, pero al mismo tiempo se copia al directorio de paquetes preservados. |
| -warn | Muestra lo que sucedería si usted eliminara el paquete |
18.2.4 upgradepkg
upgradepkg(8) actualizará un paquete Slackware previamente instalado. La sintaxis es como sigue:
# upgradepkg nombre_del_paquete
|
o
# upgradepkg nombre_del_paquete_viejo%nombre_del_paquete_nuevo
|
upgradepkg primero instala el nuevo paquete y luego elimina el viejo, de manera que los archivos del viejo no quedan vagabundeando por el sistema. Si el nombre del paquete actualizado ha cambiado, use la sintaxis con el signo de porciento para especificar el paquete viejo (el que está instalado) y el nuevo (hacia el cual usted está actualizando).
upgradepkg no es infalible. Usted siempre debe respaldar sus archivos de configuración. Si estos son eliminados o sobrescritos, usted necesitará una copia de los originales para realizar las reparaciones.
Al igual que con installpkg y removepkg, usted puede especificar varios paquetes o utilizar comodines en el nombre del paquete.
18.2.5 rpm2tgz/rpm2targz
El sistema de gestión de paquetes de Red Hat (RPM) es uno de los más populares de los que existen hoy en día. Muchos distribuidores de software ofrecen sus productos en formato RPM. Como este no es nuestro formato nativo, no recomendamos a nadie que confíe en él. El problema radica en que algunas cosas solamente están disponibles solamente como RPM (incluso las fuentes).
Nosotros brindamos un programa que convierte los paquetes RPM en nuestro formato nativo .tgz. Esto le permitirá a usted extraer el paquete (quizás con explodepkg) hacia un directorio temporal y examinar su contenido.
El programa rpm2tgz creará un paquete Slackware con una extensión .tgz, mientras que rpm2targz creará el archivo con una extensión .tar.gz.
18.3 Haciendo Paquetes
Hacer paquetes para Slackware puede ser fácil o difícil. No existe un método específico para construir un paquete. El único requerimiento es que el paquete sea un archivo tar, comprimido con gzip, y que si existe un script de postinstalación, sea /install/doinst.sh.
Si usted está interesado en hacer paquetes para su sistema o para la red que usted gestiona, usted debe mirar los diferentes scripts para construir paquetes que se encuentran en el árbol de fuentes de Slackware. Existen muchos métodos que nosotros usamos para construir paquetes.
18.3.1 explodepkg
explodepkg(8) hará la misma cosa que installpkg hace para extraer el paquete, pero no lo instala realmente, ni lo archiva en la base de datos de paquetes. Simplemente lo extrae al directorio actual.
Si usted mira en el árbol de fuentes de Slackware, usted verá como usamos este comando para paquetes “framework”. Estos paquetes contienen un esqueleto con la forma que tendrá el paquete final. Estos almacenan todos los nombres de archivos necesarios (con tamaño cero), permisos, y propietario. El script de construcción le hará cat al contenido del paquete desde el directorio fuente hacia el directorio de construcción del paquete.
18.3.2 makepkg
makepkg(8) va a empaquetar el directorio actual en un paquete Slackware válido. Además, buscará cualquier enlace simbólico en el árbol, y adicionará un bloque para su creación en el script de postinstalación, para crearlo durante la instalación del paquete. Además, advierte sobre cualquier archivo de longitud cero en el árbol del paquete.
Este comando se ejecuta típicamente después de que usted ha creado el árbol del paquete.
18.3.3 Scripts SlackBuild
Los paquetes de Slackware se construyen de muchas maneras diferentes, según la necesidad. No todos los paquetes de software son escritos por sus programadores para que compilen de la misma manera. Muchos tienen opciones de compilación que no están incluidas en los paquetes que Slackware usa. Quizás usted necesita alguna de estas funcionalidades; entonces, usted necesitará compilar su propio paquete. Afortunadamente, para muchos paquetes de Slackware, usted puede encontrar los scripts SlackBuild en el código fuente de los paquetes.
¿Entonces, qué es un script SlackBuild? Los scripts SlackBuild son comandos de consola ejecutables que usted debe correr como root para configurar, compilar y crear paquetes de Slackware. Usted puede modificar libremente estos scripts en el directorio fuente y correrlos después para crear su propia versión del paquete de Slackware por omisión.
18.4 Haciendo Tags y Archivos de tags (para setup)
El programa setup de Slackware maneja la instalación de los paquetes de software en su sistema. Existen archivos que le dicen a setup que paquetes deben ser instalados, cuales de ellos son opcionales y cuales son seleccionados por omisión por el programa setup.
Un tagfile (archivo tag) está en el directorio de la primera serie de software u se denomina tagfile. Este lista los paquetes en ese grupo de discos en particular, y su estado. El estado puede ser:
Tabla 18-3. Opciones de estado del archivo de Tags
| Opción | Significado |
|---|---|
| ADD | El paquete es requerido para la operación adecuada del sistema |
| SKP | El paquete será saltado automáticamente |
| REC | El paquete no es requerido, pero es recomendado |
| OPT | El paquete es opcional |
package_name: status |
Capítulo 19 ZipSlack
19.1 ¿Qué es ZipSlack?
ZipSlack es una versión especial de Slackware Linux. Es una copia ya instalada de Slackware lista para correr desde la partición Windows o DOS de su computadora. Es una instalación básica, así que usted no tendrá todo lo que viene con Slackware.
ZipSlack obtiene su nombre de la forma en que se distribuye: en un gran archivo .ZIP. Los usuarios de DOS y Windows probablemente se sientan a gusto con este tipo de archivos. Son archivos comprimidos. El archivo ZipSlack contiene todo lo necesario para levantar y correr un Slackware.
Es importante notar que ZipSlack es significativamente diferente de una instalación regular. Incluso cuando tenga las mismas funcionalidades y contenga los mismos paquetes, sus audiencias y funciones difieren. A continuación, se discuten varias de las ventajas y desventajas de ZipSlack.
Un último detalle: siempre revise la documentación incluida en el directorio de ZipSlack. Esta contiene la última información acerca de la instalación, inicio y uso general del producto.
19.1.1 Ventajas
-
No requiere que usted reparticione su disco duro.
-
Una excelente manera de aprender Slackware Linux sin pasar por los tropiezos del proceso de instalación.
19.1.2 Desventajas
-
Utiliza el sistema de archivos de DOS, el cual es mucho más lento que un sistema de archivos nativo Linux.
-
No funciona con Windows NT.
19.2 Obteniendo ZipSlack
Obtener ZipSlack es fácil. Si usted ha comprado el juego de CDs oficiales de Slackware, entonces ya tiene ZipSlack. Solamente busque el CD que contiene el directorio zipslack y póngalo en su lector de CD-ROM. Es usualmente el tercero o cuarto disco, pero siempre mire la documentación en las etiquetas de los discos, pues su ubicación es propensa a cambiar.
Si usted desea descargar ZipSlack, primero debe visitar nuestra página web “Get Slack” donde encontrará la última información para descargar:
http://www.slackware.com/getslack/
ZipSlack forma parte de cada una de las versiones de Slackware. Busque la versión que desee y vaya a ese directorio del sitio FTP. El directorio con la última versión puede encontrarse en la siguiente dirección:
ftp://ftp.slackware.com/pub/slackware/slackware/
Usted encontrará ZipSlack en el subdirectorio /zipslack. ZipSlack es ofrecido como un gran archivo .ZIP o en pedacitos del tamaño de un disquete. Los pedacitos se encuentran en el directorio /zipslack/split.
No se detenga solamente en los archivos .ZIP. Usted debe además descargar los archivos de documentación y cualquier imagen de inicio que aparezca en el directorio.
19.2.1 Instalación
Una vez que usted haya descargado los componentes necesarios, usted necesitará extraer el archivo .ZIP. Asegúrese de usar un descompactador de 32 bits. El tamaño y los nombres de archivos son demasiado para un descompactador de 16-bit. Ejemplos de descompactadores de 32-bit son WinZip y PKZIP para Windows.
ZipSlack está diseñado para ser extraído directamente en el directorio raíz de una unidad (como C: o D:). Será creado un directorio \LINUX que contendrá la instalación de Slackware. Usted también encontrará los archivos necesarios para iniciar el sistema en dicho directorio.
Después de haber extraído los archivos, usted debe tener un directorio \LINUX en la unidad que usted haya seleccionado (usaremos C: de aquí en adelante).
19.3 Iniciando ZipSlack
Existen muchas maneras de iniciar ZipSlack. La más común es usar el archivo LINUX.BAT para iniciar el sistema desde DOS (o desde el modo DOS bajo Windows 9x). Este archivo debe ser editado para que corresponda a su sistema antes de ponerlo a funcionar.
Comience abriendo el archivo C:\LINUX\LINUX.BAT en su editor de texto favorito. Al inicio de este archivo usted notará un gran comentario. Este explica lo que usted necesita editar en este archivo (y también lo que debe hacer si está iniciando desde una unidad Zip externa). No se preocupe si usted no entiende la configuración root=. Existen muchos ejemplos, así que escoja uno y pruebe. Si no funciona, puede editar el archivo de nuevo, comentar la línea que usted descomentó, y seleccionar otra.
Después de descomentar la línea que usted desee eliminando el “rem” al inicio de la línea, salve el archivo y salga del editor. Ponga su máquina en modo DOS.
Una ventana de comandos DOS en Windows 9x NO funciona.
Teclee C:\LINUX\LINUX.BAT para iniciar el sistema. Si todo funciona bien, usted debe ver un prompt de inicio de sesión.
Inicie sesión como root, sin contraseña. Usted probablemente desee poner una contraseña para root, así como adicionar una cuenta para su uso. Llegado a ese punto, usted puede consultar otras secciones de este libro para conocer sobre el uso general del sistema.
Si LINUX.BAT no le funcionó, usted debe referirse al archivo C:\LINUX\README.1ST, donde encontrará otras maneras de iniciar.
Glosario
- Archivo punto
-
En Linux, los archivos que deben ser ocultos tienen nombres que comienzan con un punto ('.').
- Archivo Tag
- Biblioteca
-
Colección de funciones que pueden compartirse entre programas.
- Cargador Dinámico
- Código Fuente
- Comando interno
- Compilar
-
Convertir código fuente a código binario, legible para la máquina.
- Consola
- Consola Segura
- Controlador de Dispositivo
-
Porción de código en el núcleo que controla directamente determinada pieza de hardware.
- Cuenta
- Darkstar
- Demonio
- Directorio de trabajo
-
Directorio en el cual un programa considera que él mismo se encuentra mientras corre.
- Directorio Home
- Directorio Raíz
- Disco de inicio
- Disco Root
-
El disco (normalmente fijo) en el cual se almacena el directorio raíz.
- Disco suplementario
- DNS
- Dotted quad
- Enlace simbólico
- Entorno de Escritorio
- Entrada Estándar (stdin)
- Época
- Error Estándar (stderr)
- Espacio de intercambio
- Framebuffer
- FTP
- Gestor de Ventanas
- GID
- Grupo
- GUI
- HOWTO
- HTTP
- ICMP
- Interfaz de Red
- LILO
- LOADLIN
- MBR
- Módulo del núcleo
- MOTD
- Motif
-
Grupo de herramientas muy populares utilizado en muchos programas viejos para X.
- NFS
- Nodo de Dispositivo
- Nombre de Dominio
-
El nombre de una computadora en el DNS, excluyendo el nombre del host.
- Núcleo
- Octal
- Paginador
-
Programa de X que permite que el usuario vea e intercambie entre diferentes “escritorios”.
- Paquete de Software
- Partición
-
División del disco duro. Los sistemas de archivos existen encima de las particiones.
- Pasarela
-
Computadora a través de la cual los datos de una red son transferidos a otra red.
- PPP
- Primer Plano
- Proceso
- Proceso suspenso
-
Un proceso que se ha congelado hasta que sea muerto (killed) o terminado.
- Programa cubierta
- Punto de Montaje
-
Directorio vacío en un sistema de archivos donde otro sistema de archivos es “montado”, o injertado.
- Runlevel (Niveles)
- Salida Estándar (stdout)
- Sección Man
- Segundo plano
- Señal
- Series de Software
- Servicios
- Servidor de Nombres
- Servidor X
- Sistema de Archivos
- Sistema X
- SLIP
- Subred
- Suite de contraseñas Shadow
- Superbloque
- Tabla de Ruteo
- Terminal
- Terminal virtual
- Toolkit, GUI
- UID
- Variables de Entorno
- VESA
Apéndice A. La Licencia General Pública GNU
A.1. Preamble
The licenses for most software are designed to take away your freedom to share and change it. By contrast, the GNU General Public License is intended to guarantee your freedom to share and change free software--to make sure the software is free for all its users. This General Public License applies to most of the Free Software Foundation's software and to any other program whose authors commit to using it. (Some other Free Software Foundation software is covered by the GNU Library General Public License instead.) You can apply it to your programs, too.
When we speak of free software, we are referring to freedom, not price. Our General Public Licenses are designed to make sure that you have the freedom to distribute copies of free software (and charge for this service if you wish), that you receive source code or can get it if you want it, that you can change the software or use pieces of it in new free programs; and that you know you can do these things.
To protect your rights, we need to make restrictions that forbid anyone to deny you these rights or to ask you to surrender the rights. These restrictions translate to certain responsibilities for you if you distribute copies of the software, or if you modify it.
For example, if you distribute copies of such a program, whether gratis or for a fee, you must give the recipients all the rights that you have. You must make sure that they, too, receive or can get the source code. And you must show them these terms so they know their rights.
We protect your rights with two steps: (1) copyright the software, and (2) offer you this license which gives you legal permission to copy, distribute and/or modify the software.
Also, for each author's protection and ours, we want to make certain that everyone understands that there is no warranty for this free software. If the software is modified by someone else and passed on, we want its recipients to know that what they have is not the original, so that any problems introduced by others will not reflect on the original authors' reputations.
Finally, any free program is threatened constantly by software patents. We wish to avoid the danger that redistributors of a free program will individually obtain patent licenses, in effect making the program proprietary. To prevent this, we have made it clear that any patent must be licensed for everyone's free use or not licensed at all.
The precise terms and conditions for copying, distribution and modification follow.
A.2. TERMS AND CONDITIONS
TERMS AND CONDITIONS FOR COPYING, DISTRIBUTION AND MODIFICATION
-
This License applies to any program or other work which contains a notice placed by the copyright holder saying it may be distributed under the terms of this General Public License. The “Program”, below, refers to any such program or work, and a “work based on the Program” means either the Program or any derivative work under copyright law: that is to say, a work containing the Program or a portion of it, either verbatim or with modifications and/or translated into another language. (Hereinafter, translation is included without limitation in the term “modification”.) Each licensee is addressed as “you”.
Activities other than copying, distribution and modification are not covered by this License; they are outside its scope. The act of running the Program is not restricted, and the output from the Program is covered only if its contents constitute a work based on the Program (independent of having been made by running the Program). Whether that is true depends on what the Program does.
-
You may copy and distribute verbatim copies of the Program's source code as you receive it, in any medium, provided that you conspicuously and appropriately publish on each copy an appropriate copyright notice and disclaimer of warranty; keep intact all the notices that refer to this License and to the absence of any warranty; and give any other recipients of the Program a copy of this License along with the Program.
You may charge a fee for the physical act of transferring a copy, and you may at your option offer warranty protection in exchange for a fee.
-
You may modify your copy or copies of the Program or any portion of it, thus forming a work based on the Program, and copy and distribute such modifications or work under the terms of Section 1 above, provided that you also meet all of these conditions:
-
You must cause the modified files to carry prominent notices stating that you changed the files and the date of any change.
-
You must cause any work that you distribute or publish, that in whole or in part contains or is derived from the Program or any part thereof, to be licensed as a whole at no charge to all third parties under the terms of this License.
-
If the modified program normally reads commands interactively when run, you must cause it, when started running for such interactive use in the most ordinary way, to print or display an announcement including an appropriate copyright notice and a notice that there is no warranty (or else, saying that you provide a warranty) and that users may redistribute the program under these conditions, and telling the user how to view a copy of this License. (Exception: if the Program itself is interactive but does not normally print such an announcement, your work based on the Program is not required to print an announcement.)
These requirements apply to the modified work as a whole. If identifiable sections of that work are not derived from the Program, and can be reasonably considered independent and separate works in themselves, then this License, and its terms, do not apply to those sections when you distribute them as separate works. But when you distribute the same sections as part of a whole which is a work based on the Program, the distribution of the whole must be on the terms of this License, whose permissions for other licensees extend to the entire whole, and thus to each and every part regardless of who wrote it.
Thus, it is not the intent of this section to claim rights or contest your rights to work written entirely by you; rather, the intent is to exercise the right to control the distribution of derivative or collective works based on the Program.
In addition, mere aggregation of another work not based on the Program with the Program (or with a work based on the Program) on a volume of a storage or distribution medium does not bring the other work under the scope of this License.
-
-
You may copy and distribute the Program (or a work based on it, under Section 2) in object code or executable form under the terms of Sections 1 and 2 above provided that you also do one of the following:
-
Accompany it with the complete corresponding machine-readable source code, which must be distributed under the terms of Sections 1 and 2 above on a medium customarily used for software interchange; or,
-
Accompany it with a written offer, valid for at least three years, to give any third party, for a charge no more than your cost of physically performing source distribution, a complete machine-readable copy of the corresponding source code, to be distributed under the terms of Sections 1 and 2 above on a medium customarily used for software interchange; or,
-
Accompany it with the information you received as to the offer to distribute corresponding source code. (This alternative is allowed only for noncommercial distribution and only if you received the program in object code or executable form with such an offer, in accord with Subsection b above.)
The source code for a work means the preferred form of the work for making modifications to it. For an executable work, complete source code means all the source code for all modules it contains, plus any associated interface definition files, plus the scripts used to control compilation and installation of the executable. However, as a special exception, the source code distributed need not include anything that is normally distributed (in either source or binary form) with the major components (compiler, kernel, and so on) of the operating system on which the executable runs, unless that component itself accompanies the executable.
If distribution of executable or object code is made by offering access to copy from a designated place, then offering equivalent access to copy the source code from the same place counts as distribution of the source code, even though third parties are not compelled to copy the source along with the object code.
-
-
You may not copy, modify, sublicense, or distribute the Program except as expressly provided under this License. Any attempt otherwise to copy, modify, sublicense or distribute the Program is void, and will automatically terminate your rights under this License. However, parties who have received copies, or rights, from you under this License will not have their licenses terminated so long as such parties remain in full compliance.
-
You are not required to accept this License, since you have not signed it. However, nothing else grants you permission to modify or distribute the Program or its derivative works. These actions are prohibited by law if you do not accept this License. Therefore, by modifying or distributing the Program (or any work based on the Program), you indicate your acceptance of this License to do so, and all its terms and conditions for copying, distributing or modifying the Program or works based on it.
-
Each time you redistribute the Program (or any work based on the Program), the recipient automatically receives a license from the original licensor to copy, distribute or modify the Program subject to these terms and conditions. You may not impose any further restrictions on the recipients' exercise of the rights granted herein. You are not responsible for enforcing compliance by third parties to this License.
-
If, as a consequence of a court judgment or allegation of patent infringement or for any other reason (not limited to patent issues), conditions are imposed on you (whether by court order, agreement or otherwise) that contradict the conditions of this License, they do not excuse you from the conditions of this License. If you cannot distribute so as to satisfy simultaneously your obligations under this License and any other pertinent obligations, then as a consequence you may not distribute the Program at all. For example, if a patent license would not permit royalty-free redistribution of the Program by all those who receive copies directly or indirectly through you, then the only way you could satisfy both it and this License would be to refrain entirely from distribution of the Program.
If any portion of this section is held invalid or unenforceable under any particular circumstance, the balance of the section is intended to apply and the section as a whole is intended to apply in other circumstances.
It is not the purpose of this section to induce you to infringe any patents or other property right claims or to contest validity of any such claims; this section has the sole purpose of protecting the integrity of the free software distribution system, which is implemented by public license practices. Many people have made generous contributions to the wide range of software distributed through that system in reliance on consistent application of that system; it is up to the author/donor to decide if he or she is willing to distribute software through any other system and a licensee cannot impose that choice.
This section is intended to make thoroughly clear what is believed to be a consequence of the rest of this License.
-
If the distribution and/or use of the Program is restricted in certain countries either by patents or by copyrighted interfaces, the original copyright holder who places the Program under this License may add an explicit geographical distribution limitation excluding those countries, so that distribution is permitted only in or among countries not thus excluded. In such case, this License incorporates the limitation as if written in the body of this License.
-
The Free Software Foundation may publish revised and/or new versions of the General Public License from time to time. Such new versions will be similar in spirit to the present version, but may differ in detail to address new problems or concerns.
Each version is given a distinguishing version number. If the Program specifies a version number of this License which applies to it and “any later version”, you have the option of following the terms and conditions either of that version or of any later version published by the Free Software Foundation. If the Program does not specify a version number of this License, you may choose any version ever published by the Free Software Foundation.
-
If you wish to incorporate parts of the Program into other free programs whose distribution conditions are different, write to the author to ask for permission. For software which is copyrighted by the Free Software Foundation, write to the Free Software Foundation; we sometimes make exceptions for this. Our decision will be guided by the two goals of preserving the free status of all derivatives of our free software and of promoting the sharing and reuse of software generally.
-
NO WARRANTY
BECAUSE THE PROGRAM IS LICENSED FREE OF CHARGE, THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM “AS IS” WITHOUT WARRANTY OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
-
IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MAY MODIFY AND/OR REDISTRIBUTE THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO LOSS OF DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS), EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES.
END OF TERMS AND CONDITIONS
A.3. How to Apply These Terms to Your New Programs
If you develop a new program, and you want it to be of the greatest possible use to the public, the best way to achieve this is to make it free software which everyone can redistribute and change under these terms.
To do so, attach the following notices to the program. It is safest to attach them to the start of each source file to most effectively convey the exclusion of warranty; and each file should have at least the “copyright” line and a pointer to where the full notice is found.
<one line to give the program's name and a brief idea of what it does.> |
Also add information on how to contact you by electronic and paper mail.
If the program is interactive, make it output a short notice like this when it starts in an interactive mode:
Gnomovision version 69, Copyright (C) year name of author |
The hypothetical commands `show w' and `show c' should show the appropriate parts of the General Public License. Of course, the commands you use may be called something other than `show w' and `show c'; they could even be mouse-clicks or menu items--whatever suits your program.
You should also get your employer (if you work as a programmer) or your school, if any, to sign a “copyright disclaimer” for the program, if necessary. Here is a sample; alter the names:
Yoyodyne, Inc., hereby disclaims all copyright interest in the program |
This General Public License does not permit incorporating your program into proprietary programs. If your program is a subroutine library, you may consider it more useful to permit linking proprietary applications with the library. If this is what you want to do, use the GNU Library General Public License instead of this License.